开创文章
1.扩散模型(diffusion models)Denoising Diffusion Probabilistic Models
参考知乎https://www.zhihu.com/question/545764550/answer/2670611518
1.扩散模型原理
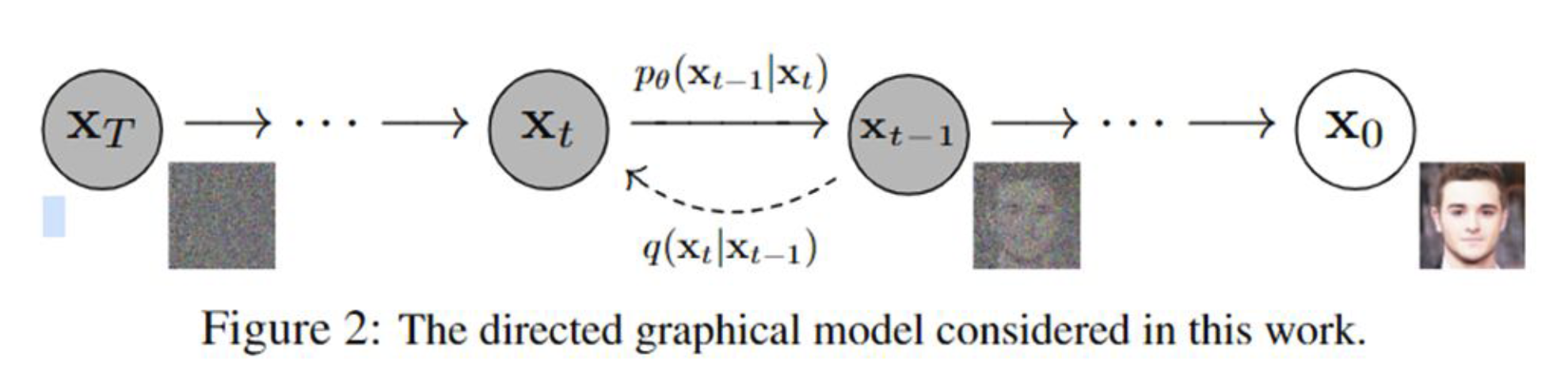
扩散模型包括两个阶段,从原图逐步到噪声的正向过程/扩散过程(forward/diffusion process)和从噪声逐步到原图的逆向过程(reverse process)。无论是正向还是反向过程都是一个参数化的马尔可夫链。利用扩散加噪生成训练样本;推理的时候,输入一个噪音,逐步去除噪音输出原始信号。
1.1随机过程
- 了解马尔可夫链之前,先要了解随机过程。主要就是个过程,比如今天下雨,那么明天下不下雨呢?后天下不下雨呢?从今天下雨到明天不下雨再到后天下雨,这就是个过程。那么怎么预测N天后到底下不下雨呢?这其实是可以利用公式进行计算的,随机过程就是这样一个工具,把整个过程进行量化处理,用公式就可以推导出来N天后的天气状况,下雨的概率是多少,不下雨的概率是多少。说白了,随机过程就是一些统计模型,利用这些统计模型可以对自然界的一些事物进行预测和处理,比如天气预报,比如股票。
1.2马尔可夫链(Markov Chain)
引用https://zhuanlan.zhihu.com/p/26453269
- 它是随机过程中的一种过程。例如王二狗只有三个状态:吃、玩、睡。这就是状态分布。

- 如果想知道他n天后的状态是什么,这些状态发生的概率是多少?引出转移矩阵P,他每个状态转移都是有概率的,比如今天玩,明天吃的概率为0.1等等。这个矩阵是保持不变的,也就是第一天到第二天的矩阵和第二天到第三天的矩阵是一样的。有了这个矩阵,加上已知的第一天的状态分布,就可以计算出第N天的状态分布了。
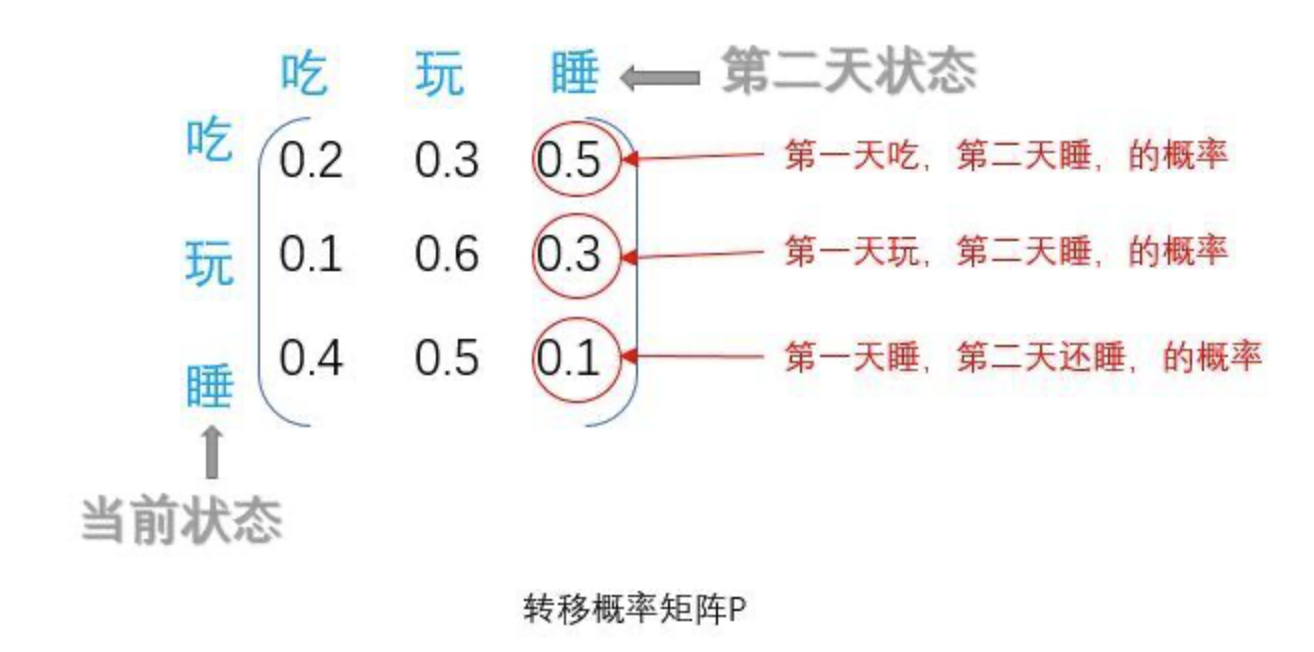
- S1是第一天的状态分布矩阵,分别代表吃玩睡的概率。第2天的状态分布矩阵$ S2 = S1 * P$ (俩矩阵相乘)。第3天的状态分布矩阵$ S3 = S2 * P$ (跟S1无关,只跟S2有关)。第n天的状态分布矩阵 (看见没,只跟它前面一个状态Sn-1有关)。
- 所以,马尔可夫链就是一个这样的过程,他将来的状态只取决于现在,跟过去无关。

1.3扩散过程
扩散过程是指对数据逐渐增加高斯噪音直至数据变成随机噪音的过程。对于原始数据,总共包含步的扩散过程的每一步都是对上一步得到的数据按如下方式增加高斯噪音:
这里为每一步所采用的方差,它介于0~1之间。t步图像由t-1步的数据添加高斯噪声得到。对于扩散模型,我们往往称不同step的方差设定为variance schedule或者noise schedule,通常情况下,越后面的step会采用更大的方差,即满足。在一个设计好的variance schedule下,如果扩散步数足够大,那么最终得到的就完全丢失了原始数据而变成了一个随机噪音。 扩散过程的每一步都生成一个带噪音的数据,整个扩散过程也就是一个马尔卡夫链:

扩散过程往往是固定的,即采用一个预先定义好的方差序列,DDPM采用一个线性的方差序列。
- 扩散过程的一个重要特性是我们可以直接基于原始数据来对任意步的进行采样,下面这个公式可以求出到的值,为随机噪音
- 可以被看作是原始数据和随机噪音的线性组合,平方和为1。
1.4反向过程
- 反向过程是一个去噪的过程,如果我们知道反向过程中的每一步的真实分布,那么从一个随机噪音开始,逐渐去噪就能生成一个真实的样本,所以反向过程也就是生成数据的过程。是单位矩阵。

- 估计分布需要用到整个训练样本,利用神经网络来估计这些分布。
这里,而为参数化的高斯分布,它们的均值和方差由训练的网络和给出。实际上,扩散模型就是要得到这些训练好的网络,因为它们构成了最终的生成模型。
1.5优化目标
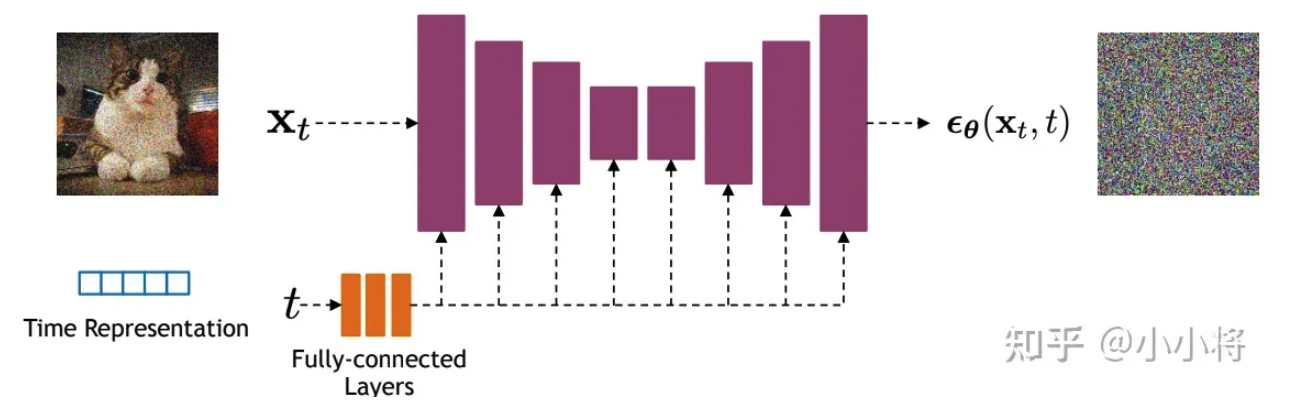
DDPM的训练过程非常简单,如下图所示:随机选择一个训练样本->从1-T随机抽样一个t->随机产生噪音-计算当前所产生的带噪音数据(红色框所示)->输入网络预测噪音->计算产生的噪音和预测的噪音的L2损失->计算梯度并更新网络。
- 训练是扩散,取样是去噪。

一旦训练完成,其采样过程也非常简单,如上所示:我们从一个随机噪音开始,并用训练好的网络预测噪音,然后计算条件分布的均值(红色框部分),然后用均值加标准差乘以一个随机噪音,直至t=0完成新样本的生成(最后一步不加噪音)。
2.模型设计
- DDPM采用的是一个基于残差块和注意力块的U-Net结构。加入了跳跃连接。输出噪音预测。
2.Denoising Diffusion Implicit Models
1.DDPM与DDIM区别
- 一个扩散模型最大的缺点是需要设置较长的扩散步数才能得到好的效果,这导致了生成样本的速度较慢,比如扩散步数为1000的话,那么生成一个样本就要模型推理1000次。另外一种扩散模型DDIM(Denoising Diffusion Implicit Models),DDIM和DDPM有相同的训练目标,但是它不再限制扩散过程必须是一个马尔卡夫链,这使得DDIM可以采用更小的采样步数来加速生成过程,DDIM的另外是一个特点是从一个随机噪音生成样本的过程是一个确定的过程(中间没有加入随机噪音)。
2.DDIM
- 扩散过程的一个重要特性是可以直接用来对任意的进行采样。原始数据为0,噪音为t。
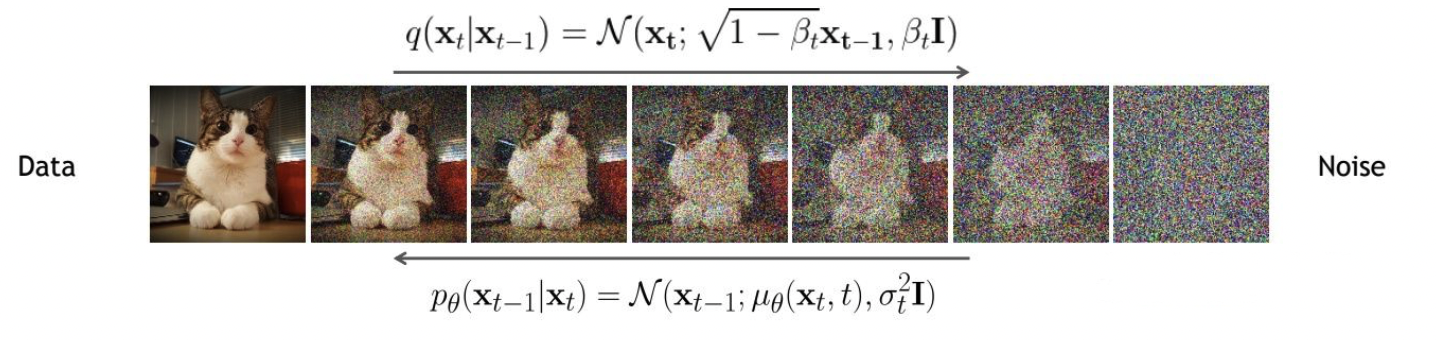
- DDPM仅依赖。所以,只要满足边缘分布条件(扩散过程的特性)即可,而这一过程不一定非要是马尔可夫链。
- DDIM中将推理分布定义为:
- 如下图采样过程所示(去噪)是一个非马尔可夫链的表示,前向过程,由于生成不仅依赖,还依赖,所以是一个非马尔可夫链
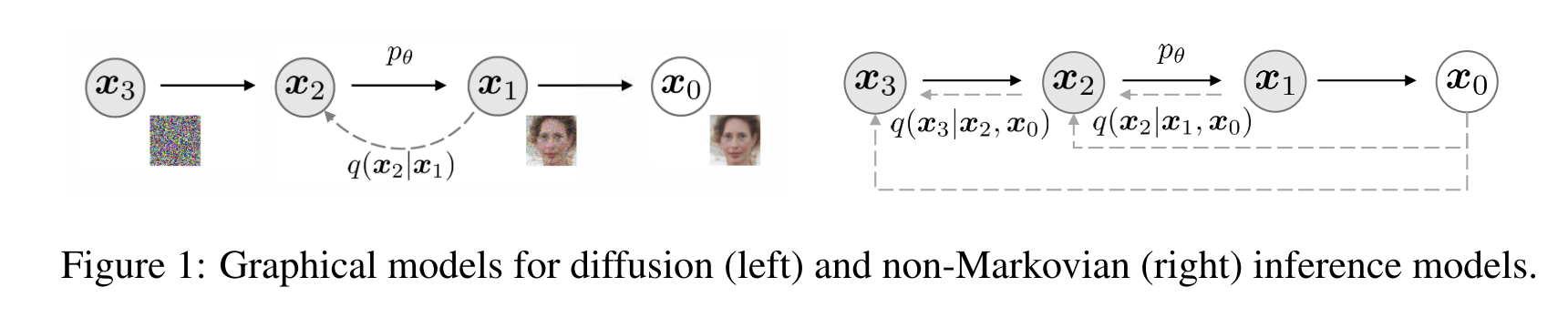
- 也利用神经网络来预测噪音,在生成阶段,用以下公式从生成:
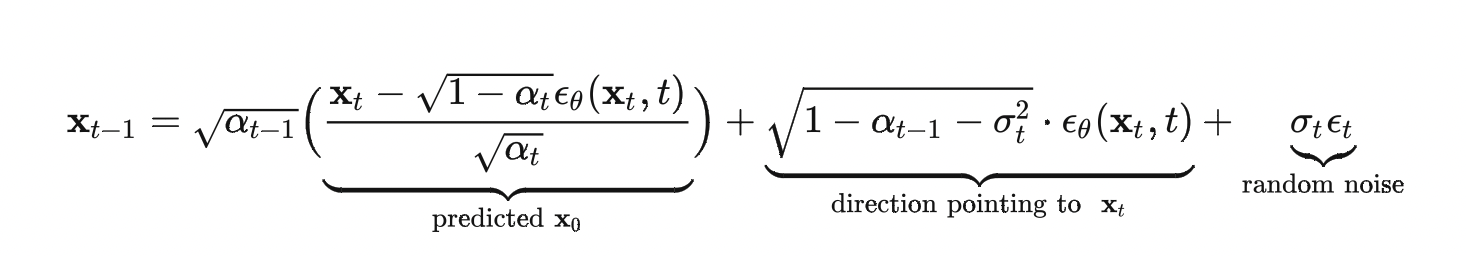
理论层面
3.NIPS2021:Diffusion Models Beat GANs on Image Synthesis
提出Classifier Guidance Diffusion Model 分类引导
- 扩散模型首次打败GAN
- **模型架构:**U-Net加一个单头全局注意力模块
- 这种方法不用额外训练扩散模型,直接在原有训练好的扩散模型上,通过外部的分类器来引导生成期望的图像。唯一需要改动的地方其实只有采样过程中的高斯采样的均值,也即采样过程中,期望噪声图像的采样中心越靠近判别器引导的条件越好。
1.类别信息指引
- 这个算法可以分成两块,一块是使用类别信息辅助模型进行噪声预测,来训练一个条件扩散模型;另一块是使用类别信息指导预训练的扩散模型进行采样。
1.1噪声预测
- 每一个时步的数据都有两个关键参数,即高斯分布的均值和方差,而扩散模型主要是使用噪声估计代替直均值估计:
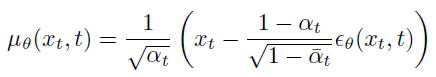
- 推导后可变为,并加入类别条件进行噪声的估计:
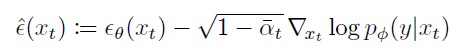
1.2分类器指导
- 分类器指导的思想与其进行噪声预测时的想法类似,主要是修改高斯分布的均值参数来指导图像按类别生成,有一个超参数表示指导的程度,算法如下:求和符号代表对角协方差矩阵,u代表均值,估计这两个参数

上图总结了采样算法。Algorithm 1 和 Algorithm 2 其实是等价的(1 是直接预测均值和方差,2 是预测噪声的误差)。直接看 Algorithm 1 可知,实质上改变的只有高斯分布的均值中心,将扩散方向“引导”成我们想要的内容。具体而言,用分类模型对生成的图片进行分类,得到预测分数与目标类别的交叉熵,将其对带噪图像求梯度用梯度引导下一步的生成采样。
2.模型架构
- U-Net加一个单头全局注意力模块
4.NIPS2021:More Control for Free! Image Synthesis with Semantic Diffusion Guidance
提出Semantic Guidance Diffusion 语义引导
- 我们可以把分类器替换成其它任意的判别器,也即更换引导条件,从而实现利用不同的语义信息来指导扩散模型的去噪过程。比如说,我们可以实现 text-guidance 和 image-guidance 等。

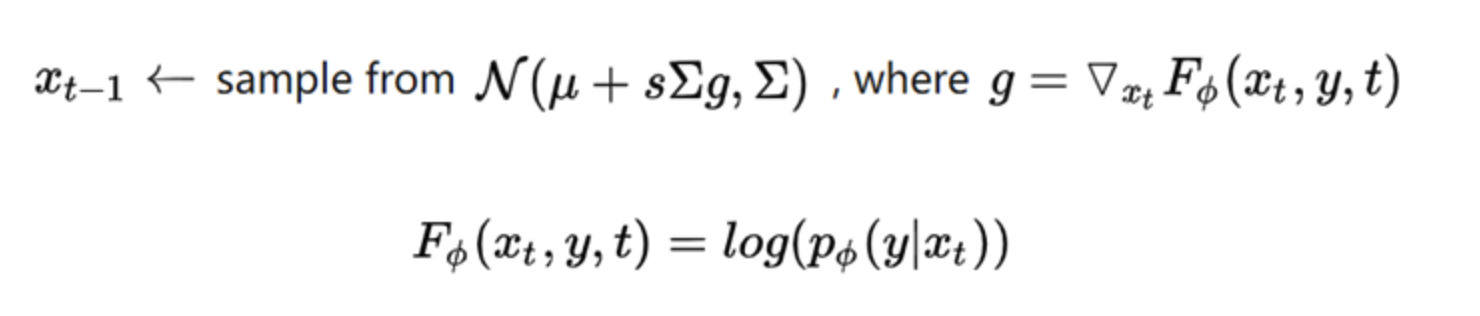
- g为新的引导条件,可以是文本也可以是图像。

5.Classifier-Free Guidance Diffusion
前面的分类引导需要额外引入一个网络来指导,推理的时候比较复杂(扩散模型需要反复迭代,每次迭代都需要额外算一个分数)。Classifier-Free Diffusion Guidance 这篇文章的贡献就是提出了一个等价的结构替换掉了外部的判别器,从而可以直接用一个扩散模型来做条件生成任务。

-
分类引导更新噪音的方式:
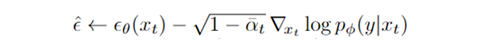
-
classifier-free利用一个等价结构替换掉了后一项:
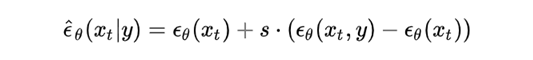
- y表示条件输入,后面的表示原有的输入。用这两项之差乘以比例系数替换原有后一项。(是根据贝叶斯公式)
下面进入应用层面
6.GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
- 利用了上一篇Classifier-Free Guidance扩散模型,把输入的condition换成了文本信息,从而实现文本生成图像。
- Text Encoder用了Transformer模型。
- 用mask的图像+text token作为condition输入到diffusion model中可以得到更好的结果。
- 基于CLIP的GLIDE模型将CLIP model替换classifier,其中CLIP也用noised image x_t训练,loss如下:
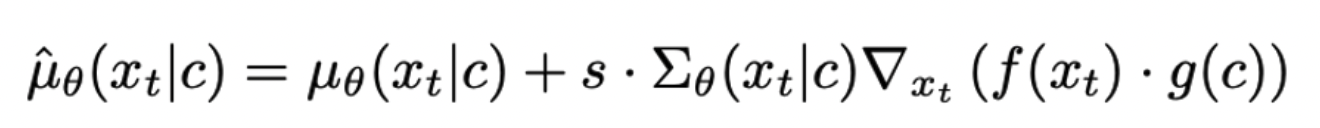

-
下公式为噪音的更新方法,把y变成caption,运用image-text对从而把caption看作label
-
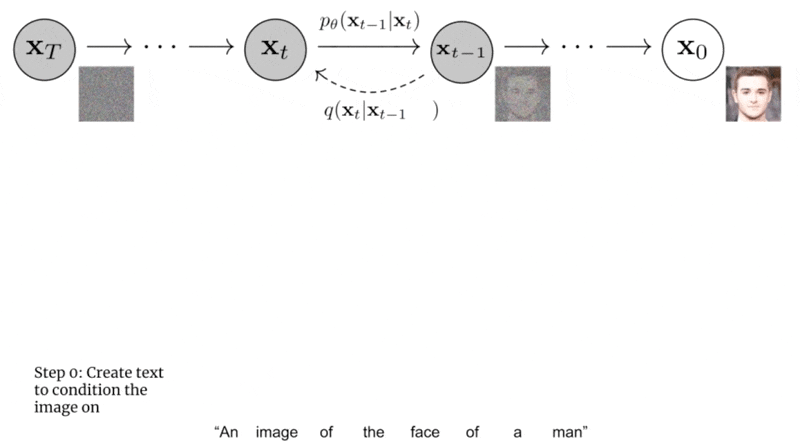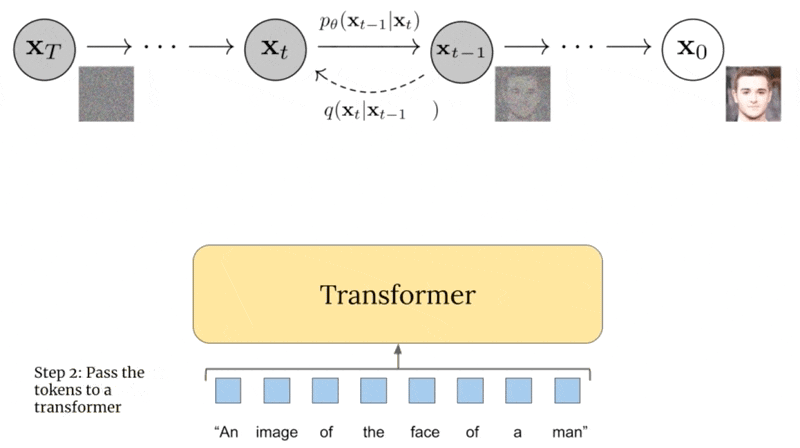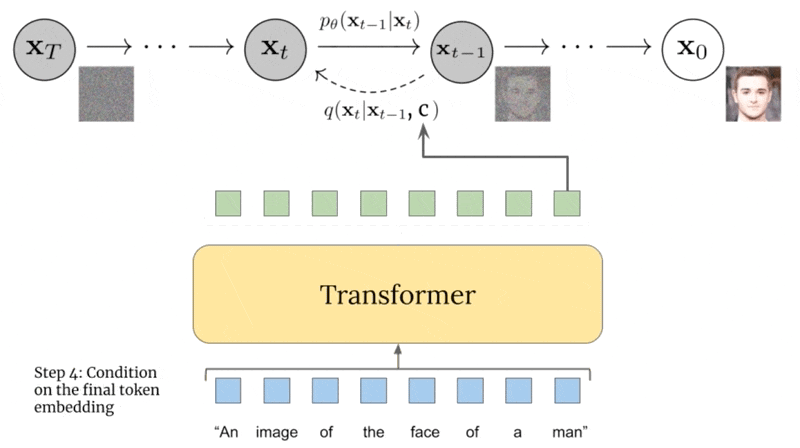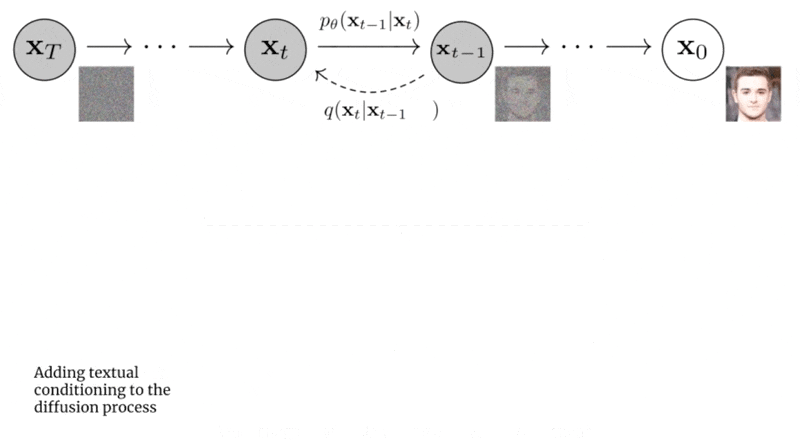
主要步骤:首先将文本编码成K个token序列
- 然后将token输入到Transformer中
- transformer输出的最后一个token作为扩散模型的条件。其中每一步中都基于生成图像与文本之间的相似度来计算梯度。且GLIDE是无分类器的扩散引导:
- 就改了下面这一个公式,大力出奇迹,2048 batchsize,250w epoch
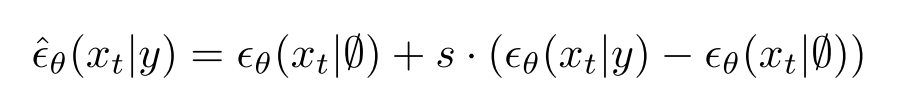
7.DALL-E-2:Hierarchical Text-Conditional Image Generation with CLIP Latents
-
DALL-E-1是GAN+CLIP。DALL- E-2是扩散模型+CLIP
-
输入:文本text。输出:生成与文本高度对应的图片
-
首先,CLIP文本编码器将图像描述映射到表示空间;
-
然后扩散先验从CLIP文本编码映射到相应的CLIP图像编码;
-
最后,修改版的GLIDE生成模型通过反向扩散从表示空间映射到图像空间,生成众多可能图像中的一个。
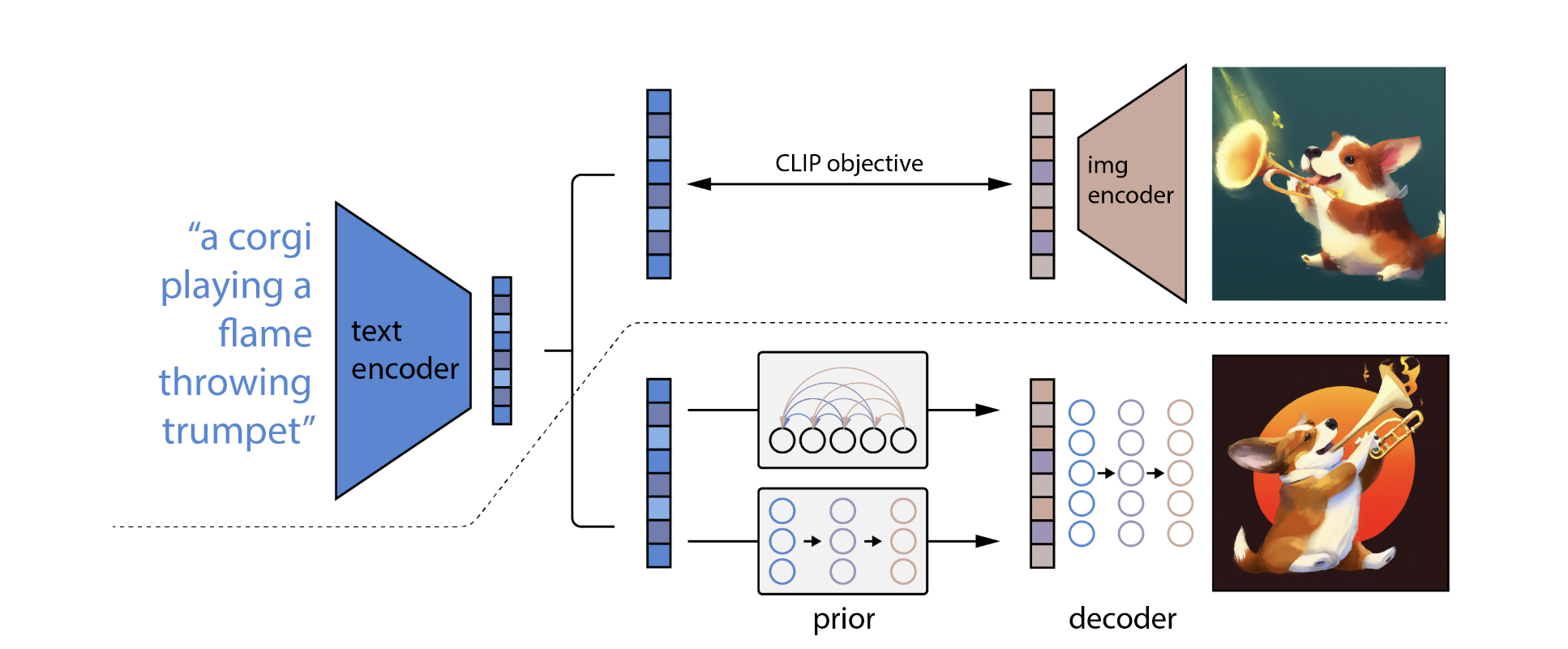
1.整体架构
- 主要包括三个部分:CLIP,先验模块prior和img decoder。其中CLIP又包含text encoder和img encoder。
- 包括 prior 网络用于将 caption 转换为 CLIP image embedding,一个decoder 把 image embedding 作为 condition 来生成图像。prior 有两种:一种是 autoregressive model、一种是 diffusion model(后者效果更好一些);decoder 就是 diffusion model。这里相比前面的变化主要在于加入了 prior,以及把 condition 换成了 CLIP 的 embedding。
2.训练过程
DALL·E 2是将其子模块分开训练的,最后将这些训练好的子模块拼接在一起,最后实现由文本生成图像的功能。
2.1CLIP,使其能够编码文本和对应图像
- 这一步是与CLIP模型的训练方式完全一样的,目的是能够得到训练好的text encoder和img encoder。这么一来,文本和图像都可以被编码到相应的特征空间。对应上图中的虚线以上部分。
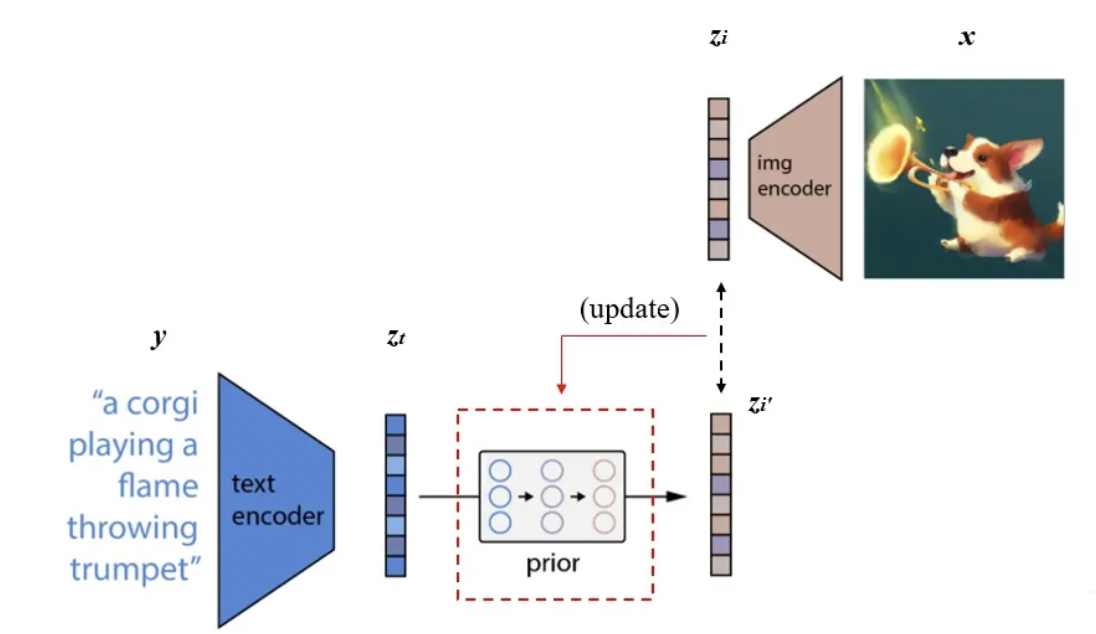
2.2Prior
A prior that produces CLIP image embeddings conditioned on captions .
- 实际的训练过程为:将CLIP中训练好的text encoder拿出来,输入文本,得到文本编码。同样的,将CLIP中训练好的img encoder拿出来,输入图像得到图像编码。我们希望prior能从获取相对应的。假设经过prior输出的特征为,那么我们自然希望与越接近越好,这样来更新我们的prior模块。最终训练好的prior,将与CLIP的text encoder串联起来,它们可以根据我们的输入文本生成对应的图像编码特征了。使用了主成分分析法PCA来提升训练的稳定性。
2.3训练decoder生成最终的图像
A decoder that produces images conditioned on CLIP image embeddings (and optionally text captions ).
- 要训练decoder模块,从图像特征还原出真实的图像,如下图左边所示。这个过程与自编码器类似,从中间特征层还原出输入图像,但又不完全一样。我们需要生成出的图像,只需要保持原始图像的显著特征就可以了,这样以便于多样化生成,例如下图右边的示例。

- DALL-E 2使用的是改进的GLIDE模型。这个模型可以根据CLIP图像编码的,还原出具有相同与有相同语义,而又不是与完全一致的图像。
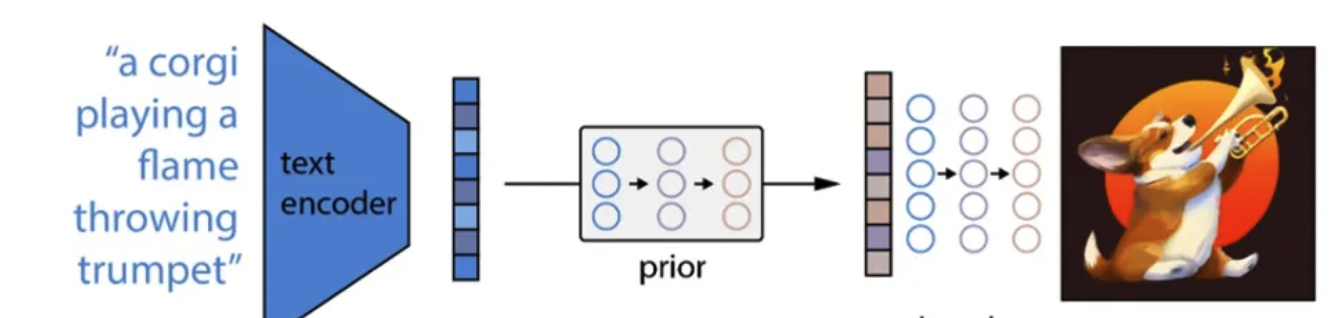
3.推理过程
- 经过以上三个步骤的训练,完成DALL·E 2预训练模型的搭建。我们这时丢掉CLIP中的img encoder,留下CLIP中的text encoder,以及新训练好的prior和decoder。由text encoder将文本进行编码,再由prior将文本编码转换为图像编码,最后由decoder进行解码生成图像。
8.CVPR2021-CLIP:Learning Transferable Visual Models From Natural Language Supervision
- 文本-图像的预训练方法
1.模型结构
- 包括两个部分,文本编码器(Text Transformer)和图像编码器(ResNet和ViT)。
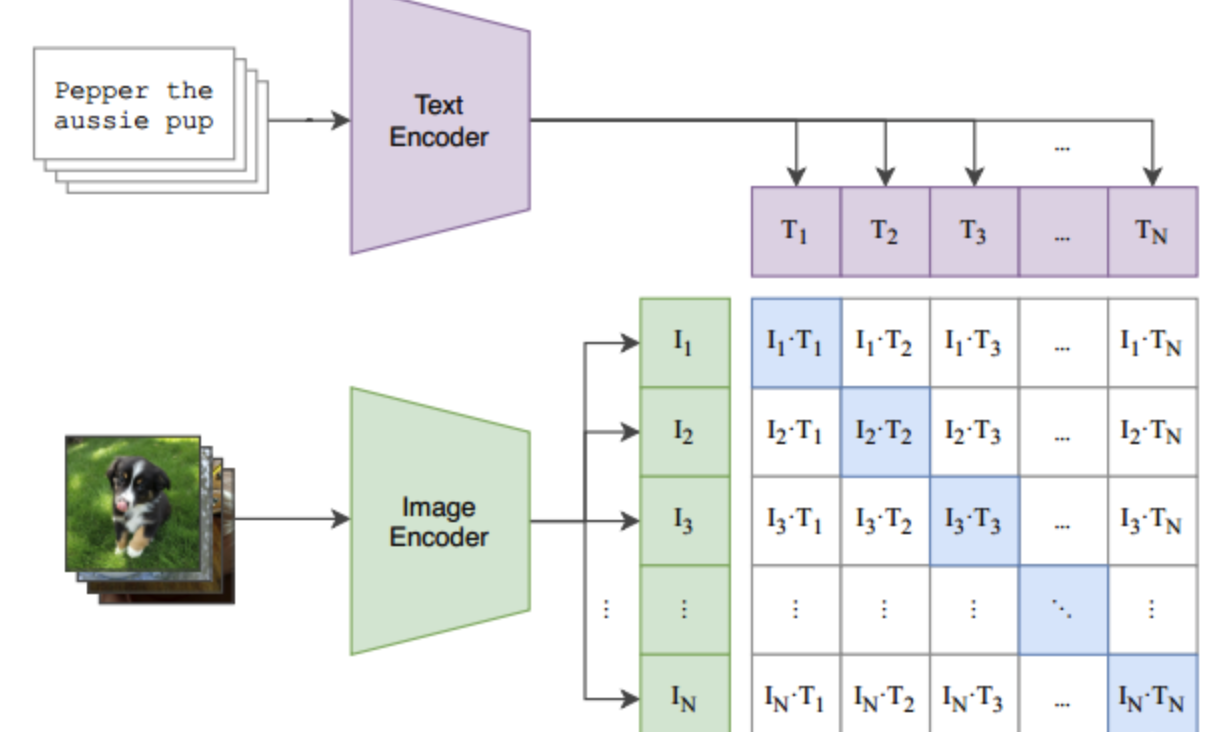
2.训练过程
- 假设DataLoader中的一个batch包含了个(文本-图像)对。将这个文本先通过Text Encoder进行文本编码,假设Text Encoder将每条文本编码为一个长度为的一维向量,那么这个batch的文本数据经Text Encoder的输出为,维度为$ (N,d_t)$ ; 同样的,将这个图像先通过Image Encoder进行图像编码,假设Image Encoder将每条文本编码为一个长度为的一维向量,那么这个batch的图像数据经Image Encoder的输出为 ,维度为 。
- 得到的和中,文本-图像是一一对应的,例如与对应,这个对应关系我们记为正样本;而原本并不对应的文本-图像我们标记为负样本,例如与不对应。这么一来,我们就有个 N 个正样本,个负样本。这样正负样本就可以作为正负标签,用来训练Text Encoder和Image Encoder了。
- 我们通过计算与之间的余弦相似度(cosine similarity) , 用来度量相应的文本与图像之间的对应关系。余弦相似度越大,表明与的对应关系越强,反之越弱。那么训练的任务为:通过训练Text Encoder和Image Encoder的参数,最大化N 个正样本的余弦相似度,最小化N2−N 个负样本的余弦相似度。按上图所示,即最大化对角线中蓝色的数值,最小化其它非对角线的数值。优化目标可以写为:
- 以上训练过程可视化如下:

- 伪代码
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
3.训练结果
- 通过大批量的文本-图像预训练后, CLIP可以先通过编码,计算输入的文本和图像的余弦相似度,来判断数据对的匹配程度。
4.迁移预训练模型实现zero-shot图像分类
-
这时CLIP已经完成了其全部训练过程,完全不需要Imagenet或其它数据集中的图像-类别标签,即可以直接做图像分类了,这也是CLIP这个模型最大的亮点:zero-shot图像分类。
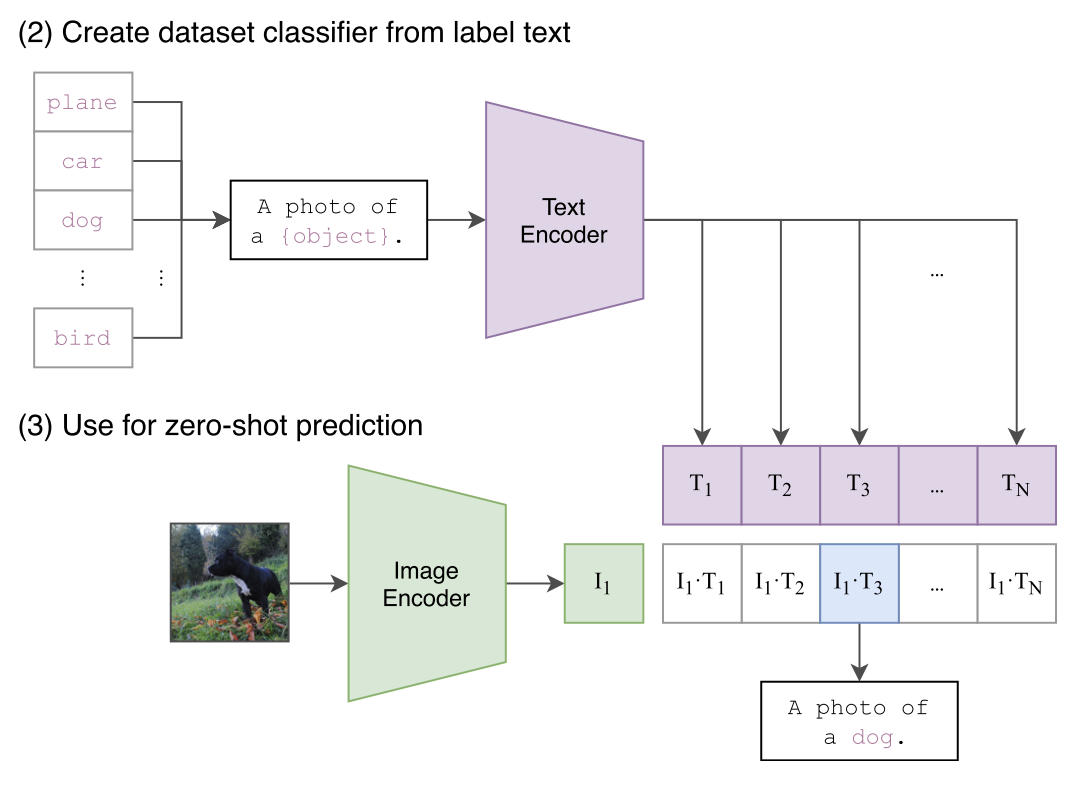
4.1分类步骤
- 根据所迁移的数据集将所有类别转换为文本。这里以Imagenet有1000类为例,我们得到了1000个文本:
A photo of {label}。我们将这1000个文本全部输入 Text Encoder中,得到1000个编码后的向量 , ,这被视作文本特征。 - 我们将需要分类的图像(单张图像)输入Image Encoder中,得到这张图像编码后的向量。将与得到的1000个文本特征分别计算余弦相似度。找出1000个相似度中最大的那一个(上图中对应的为),那么评定要分类的图片与第三个文本标签(dog)最匹配,即可将其分类为狗。
9.CVPR2022:Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
- 是google提出的,是继DALLE2的后续工作,整体框架比DALLE2简单的多。
- 可以直接用文本模型(比如本文的T5(谷歌的超大预训练模型Transfer Text-to-Text Transformer,BERT参数1.1亿,CLIP参数0.63亿,T5参数110亿),这个模型固定住不update)抽取文本的特征,利用这个特征指导扩散模型生成对应文本的图像。结合了强大的(text-only)语言模型和conditional diffusion model来做生成,可以生成高质量的图像。
- 使用dynamic thresholding来改进diffusion sampling。从而生成更真实和细节丰富的图片。
1.方法
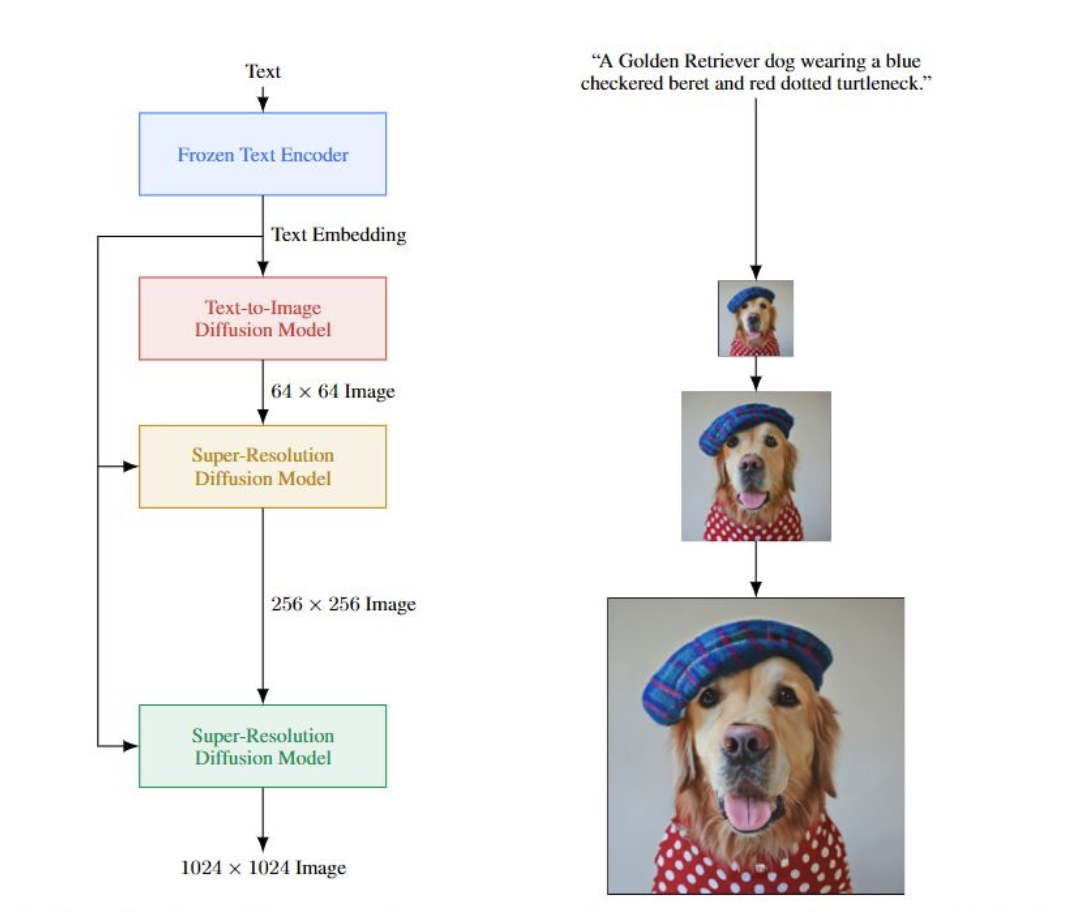
- 首先,把文本输入到text encoder中,得到text embedding(这个表达已经蕴含了所有文本信息)
- 把text embedding输入到生成模型中,其实就是给模型信息,让他基于这个信息去生成图像。第一步先成低分辨率的图像,然后再串联2个super-resolution网络,这两个网络的输入是前面的低质量图像和text embedding。最终就可以输出高质量的图像。
- 特点是把NLP中很强大的语言模型拿过来用,而不是像使用CLIP那样在image-text pair训练的text encoder。(DALLE2的做法是用一个prior网络把text encoder输出的embedding转为image encoder的输出,多了一个模型来做图文embedding的转换~)。
- 直觉上,语言模型训练的数据量远远大于image-text pair,并且其模型大小也远远大于当前的image-text模型,显然语言模型对于文本的理解能力更强,理解了文本才能生成高质量的图像。
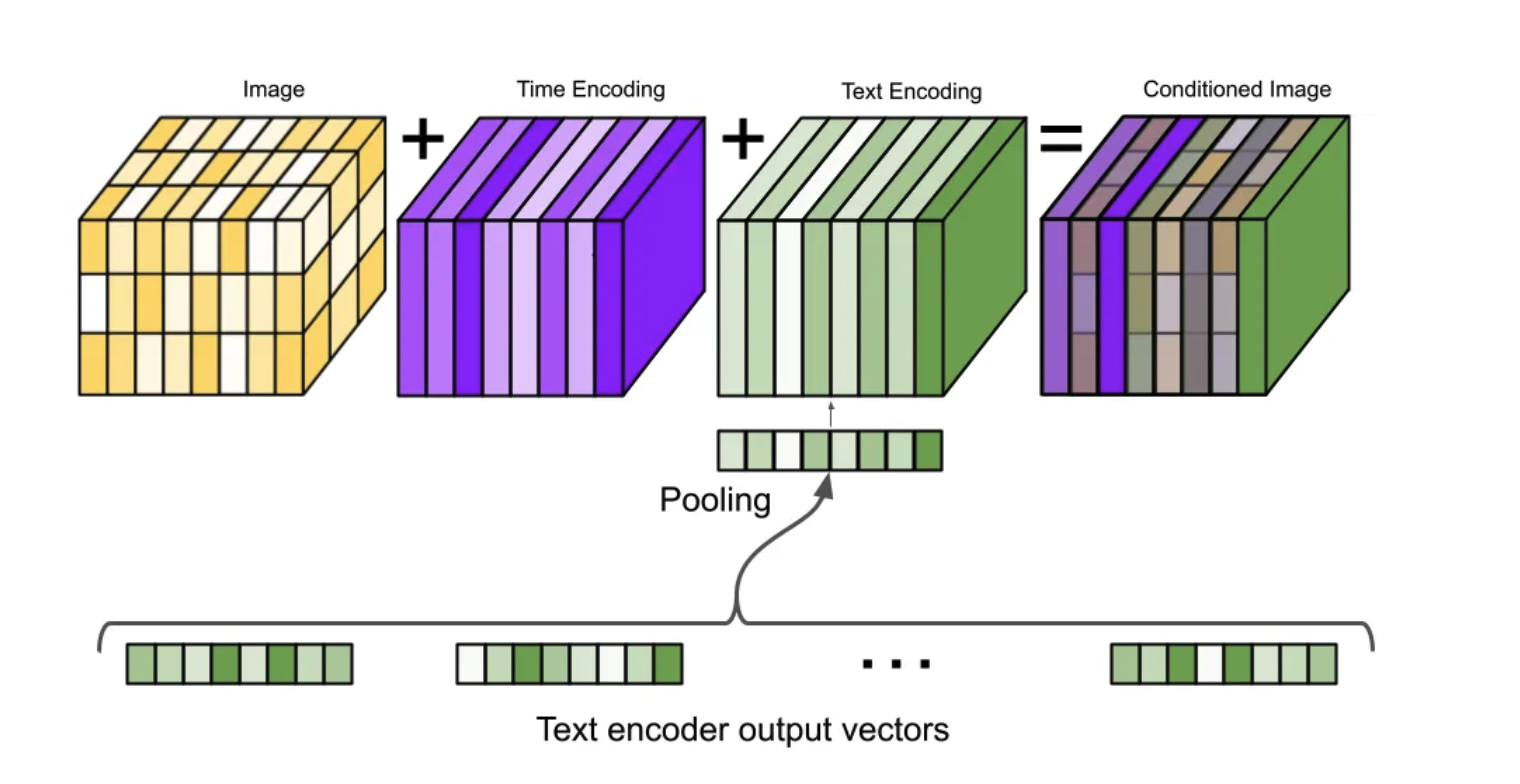
- 把text encoder抽到的文本信息做一个pooling之后,作为一个embedding加在原来的图像上从而实现condition操作。
10.High-Resolution Image Synthesis with Latent Diffusion Models
- 这篇文章的重点就在于,为什么从
pexel space到latent space是可行的——在保证减少计算成本的前提下保留了大部分扩散模型的功能,在下一节Motivation会给出解释。 - 提出直接在在特征空间上进行扩散Latent Diffusion Models(LDMs),减少复杂度,效果也还ok。
- 将扩散过程注意力机制改为cross-transformer
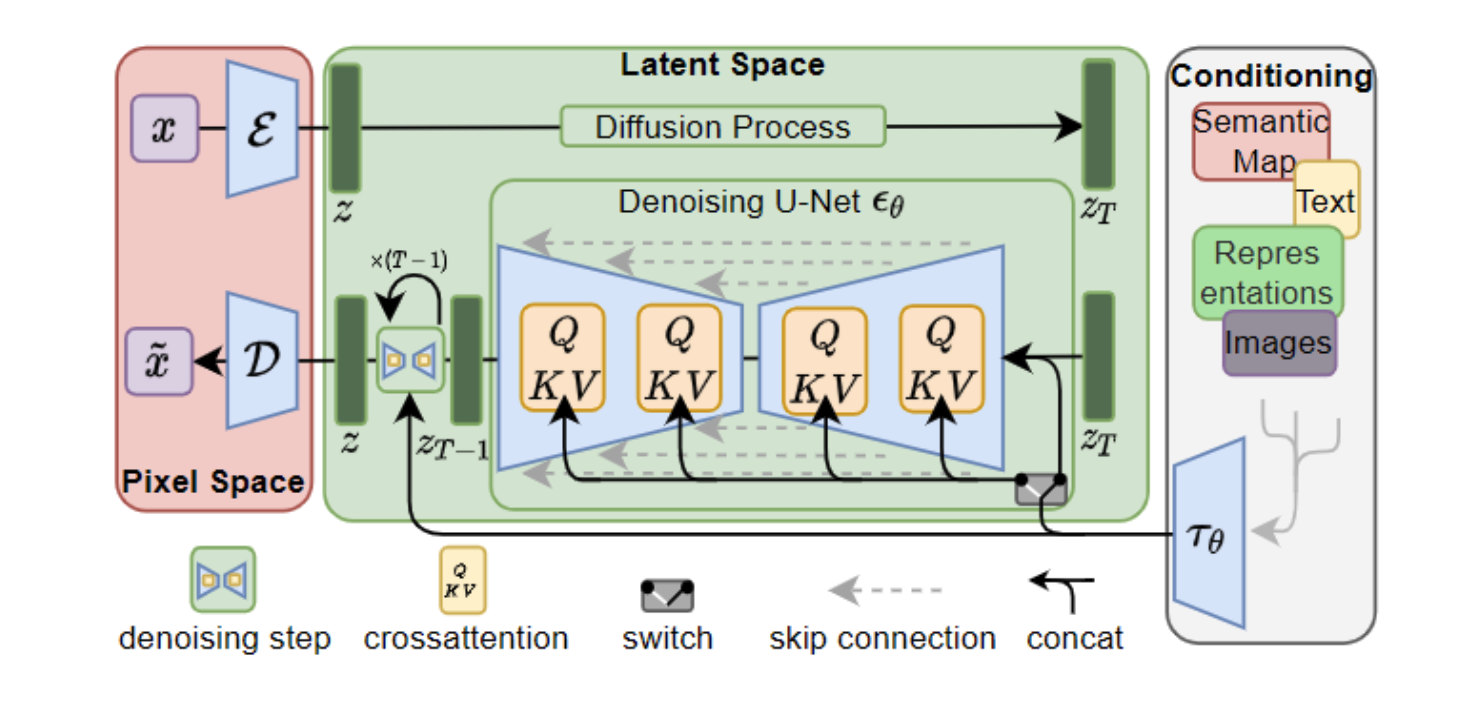
1.模型结构
- 先用一个编码器把图片压缩到隐空间,然后让扩散模型在压缩后的特征上工作,最后利用解码器还原成一张图片
- 扩散结构使用UNet结构,结合cross-attention计算。只有unet中有注意力层
- 然后利用unet结果,以文本为条件,扩散解码图像。

11.CVPR2020:Multi-Modality Cross Attention Network for Image and Sentence Matching
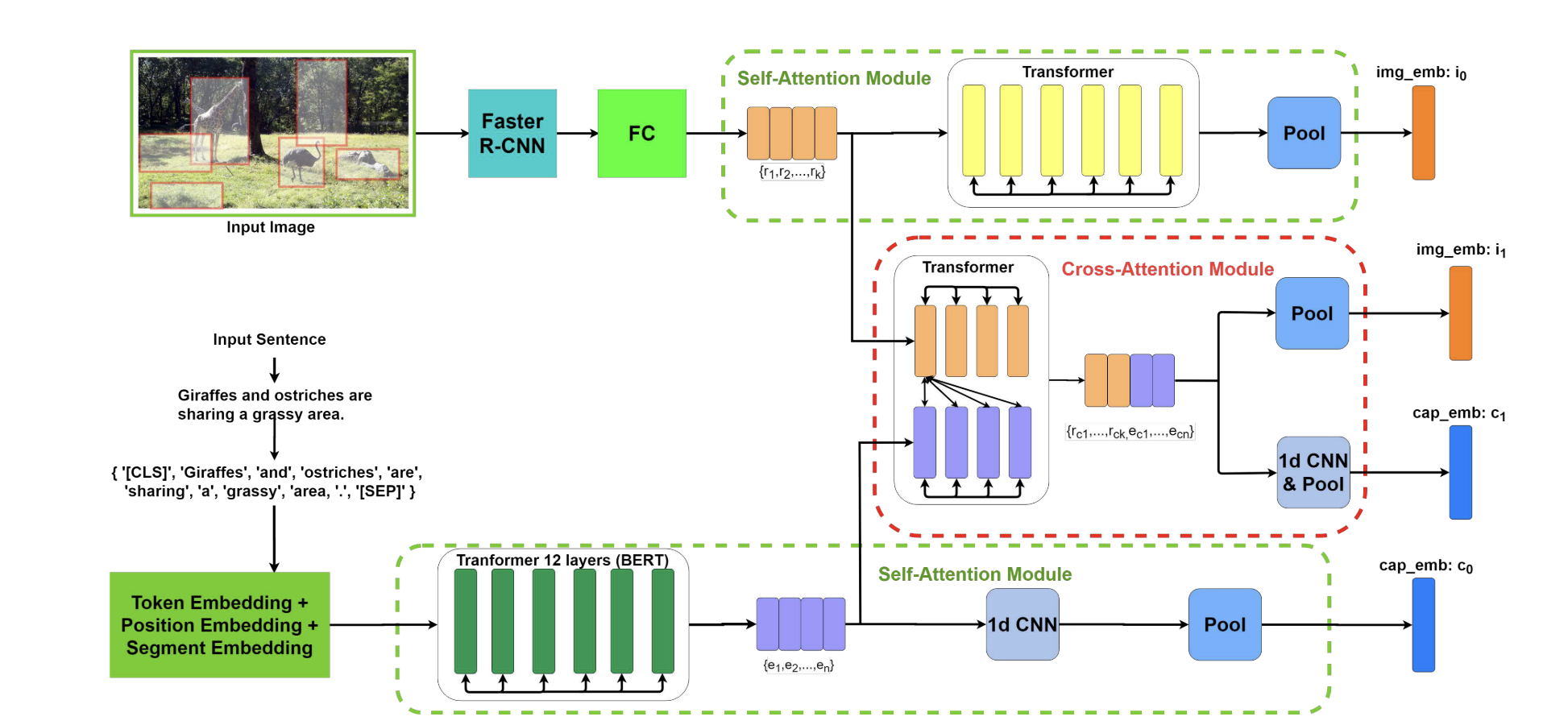
1.模型架构
- 作者提出了一种新的多模态交叉注意网络 ,通过在单一深度模型中联合建模图像区域和句子单词的模态间关系和模态内关系,实现图像和句子匹配。设计了两个有效的注意模块,包括自注意模块和交叉注意模块,它们在建模模态内和模态间的关系中起着重要作用。
- 在自注意模块中,采用自下而上的模型来提取显着图像区域的特征。同时,作者使用单词token嵌入作为语言元素。然后,独立地将图像区域输入到Transformer单元,并将单词token输入BERT模型。然后,可以通过聚合这些片段特征来获得全局表示。绿色框中为自注意力模块
- 在交叉注意模块中,作者堆叠图像区域和句子单词的表示,然后将它们传递到另一个Transformer中,然后是1d-CNN和池化操作,融合模态间和模态内信息。然后,基于视觉和文本数据的更新特征,我们可以预测输入图像和句子的相似性分数。红色框中为交叉注意力模块
1.1self-attention机制
- 计算所有自注意力的值,然后concat一起。
1.2cross-attention机制
- cross attention将图像区域和句子单词的堆叠特征作为输入
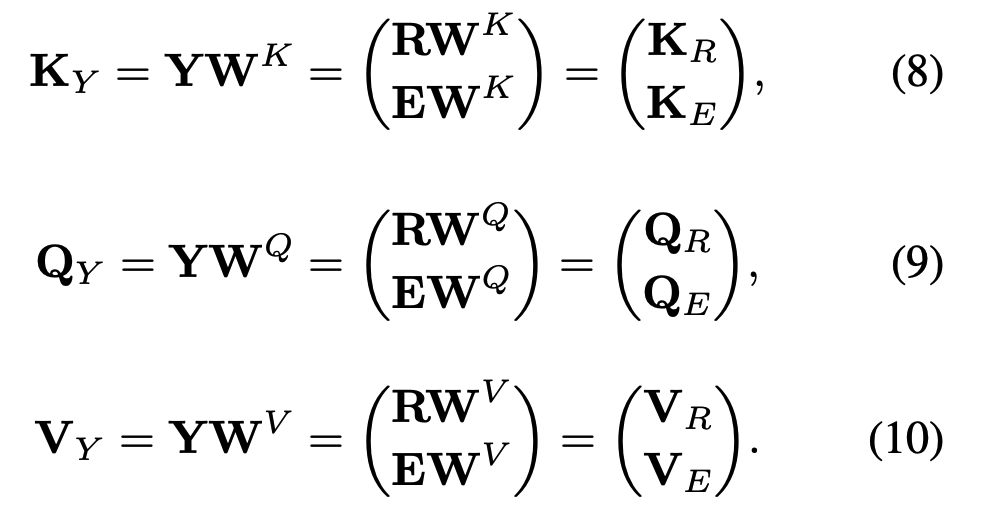




温馨提示: 遵纪守法, 友善评论!