10.26组会汇报
1.2017CVPR:Semantic Compositional Networks for Visual Captioning
语义组合网络SCN
1.摘要
- 提出一种语义组合网络SCN,从图像中检测语义概念(也就是标签),利用每个标签的概率组成LSTM中的参数。SCN将LSTM的每个权重矩阵扩展为标签相关权重矩阵集合,每个lstm参数矩阵用于生成每个标签对应图像相关的概率。
- CIDEr、BLEU-4:100.3、21.5、33.1
2.方法:SCN模型
2.1RNN
- 图像I,标题为,每个词语都是one-hot编码,特征向量提取自CNN特征,给定图像特征,描述X的概率为:

- RNN公式为如下,输入上一个单词,上一个输出,和特征向量

2.2语义概念检测
-
i:第几张图像
-
k:第几个单词
-
s:语义特征
-
语义概念为标签的检测,为了从一幅图中检测出标签,首先从训练集选择标签,选择最常出现的前k(1000)个词语。是第i个图像的标签,,k=1是第一张图像第一个单词是否出现我们把出现在描述中的单词标注为1,否则为0。和表示第i个图像特征向量和语义特征向量。
-
损失函数为:
 。是k维向量。
。是k维向量。
2.3 SCN-RNN

-
SCN将RNN的每个权重变为与标签相关的权重矩阵集合,主观的取决于标签存在于图像中的概率。$h_t = σ(W(s)x_{t−1} +U(s)h_{t−1} + z) $。W和U是依赖于语义标签的权重。
-
对于语义向量s,我们定义两个权重矩阵:Wt和Ut

-
然后把语义向量与输入和隐层输出结合。
-

2.2018CVPR:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering,4000引用
- COCO数据集格式


1.摘要
- 提出结合bottom-up和top-down的注意力机制
- bottom-up机制基于Faster R-CNN提取图像区域,每个区域有一个相关的特征向量。
- top-down机制确定特征的权重。
- CIDEr、SPICE、BLEU-4:117.9、21.5、36.9
2.介绍
-
在人类视觉系统中,注意力可以由当前任务确定自上而下的信号(例如图片中的某个物体)。也可以由意外、新颖和显著刺激来确定自下而上的信号。在文本中,将非视觉或特定于任务的上下文的注意力机制称为top-down,单纯的视觉前馈注意力机制被称为bottom-up。
-
传统使用的注意力机制都是top-down的,将上下文和图像表示为caption的输出,训练这些机制选择性的关注CNN的输出,但这些方法很少考虑如何确定受到关注的图像区域。如下图,注意力机制正常是在大小相同的区域上计算CNN特征,本文计算显著图像上的注意力。

-
自下而上提出一组显著的图像区域,每个区域由卷积特征向量表示。自下而上使用FRCNN,使注意力表达的更加自然。从上到下的机制使用特定于任务的上下文来预测图像的注意力分布,然后将参与的特征向量计算为所有向量特征的加权平均值。
3.方法
- 给定一张图片,将图像的k个特征集合作为输入,使每个图像都对显著区域进行编码。
- 3.1介绍自下而上
- 3.2介绍体系结构
- 3.3介绍VQA模型
3.1Bottom-Up Attention Model注意力模型
- RCNN:区域SS提出,特征提取,分类预测,边框回归。缺点:SS提取框大量重叠,提取特征冗余,速度慢
- Fast RCNN:一张图片生成2000候选区域SS,将整张图送入CNN,将候选区域映射到特征图上,一步就可以获得2000个区域的特征,RCNN要2000次。随机选64个,包括正负样本0.5。在进行RoI Pooling,分成7x7大小每个进行最大池化得到7x7特征矩阵,然后进行全联接得到分类结果和边界框结果。
- Faster RCNN端到端:RPN区域生成+FRCNN。输入得到特征图,使用RPN生成候选框,投影到特征图上,然后RoI,然后全连接层。每个滑动窗口中心点,生成9个anchor box,2*9,4*9参数,IoU设为0.7,最终剩下2k个,要256个anchor,正负样本1:1,anchor与GD的IoU超过0.7为正样本,小于0.3为负

- 使用FRCNN提取图片中的感兴趣点,再利用ResNet-101提取特征,使用IoU删除重叠候选框,如果大于某个阈值,说明这两个框是一个物体,就删掉它。维度2048

- Resnet101,输入3*224*224,输出2048*7*7,faster rcnn损失函数是边框和分类四个数的loss,再额外加一个多类别损失组件去训练属性。
3.2Captioning Model

- 对于top-down,每个图像的特征进行加权,使用现有部分输出序列作为上下文
- 使用两个标准LSTM组成,,xt是LSTM输入向量,ht是LSTM输出向量
3.2.1top-down attention LSTM
- 输入:上一步LSTM输出,前k个图像特征平均池化
 ,上时刻onehot编码的词语 将这三个cat,和ht-1输入。
,上时刻onehot编码的词语 将这三个cat,和ht-1输入。
3.2.2Language LSTM
- 输入:第一个LSTM的图像注意力矩阵和ht输出cat作为输入,
- 表示一个单词序列,在时间步t,可能输出单词的条件分布为:

3.2.3目标,优化loss
- 交叉熵优化
4.BUTD代码实现结果
- json文件:

- 测试图片

- 结果:
- a teddy bear sitting on the grass with a stuffed animal
- a teddy bear sitting on the ground with a stuffed animal
- a teddy bear laying on the ground with a stuffed animal
- 评估结果:
- Bleu_1: 75.0
Bleu_2: 58.6
Bleu_3: 44.8
Bleu_4: 34.1
METEOR: 26.5
ROUGE_L: 55.2
CIDEr: 106.0
- Bleu_1: 75.0
3.CVPR2019:Show, Control and Tell:A Framework for Generating Controllable and Grounded Captions
- 数据集

1.摘要
- 提出一种可控制的图像描述生成模型,可以通过外界的控制信号操控模型生成多样化的描述。具体的,模型将图像中的一组区域作为控制信号,并生成基于这些区域的图像描述。

2.方法
- 一个句子可以被认为是一个词的序列:进行区分视觉词(图像中存在的实体单词boy、cap、shirt等)和文本词(图像中没有对应实体的单词a、with、on等)。进一步,句子中的每个名词可以和修饰词组成一个名词块

2.1生成可控描述
- 给定图像I和区域有序序列集合R,生成的句子y描述R中的所有区域。
- 输入:图像I和区域序列R,R充当控制信号控制生个生成过程,联合预测句子词级和块级概率分布
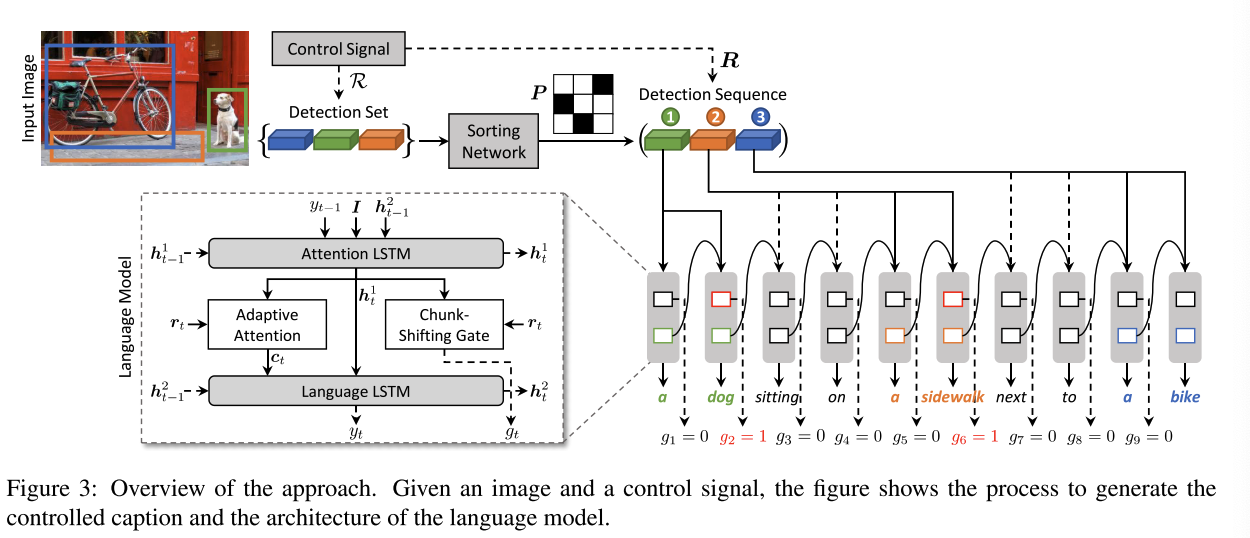
2.2Region序列
- region序列关系到整个模型的生成质量,首先要解决两个问题:1⃣️region如何得到(利用Faster- RCNN进行目标检测)。2⃣️region的序列如何控制(提出一个sorting network进行排序)。
- 排序网络:输入:目标检测特征(2048)、GloVe(Global Vectors for Word Representation把一个单词表达成实数组成的向量)提取文字特征(300维)、目标框大小和位置(4维)。最终映射到一个N维描述向量(几个区域几个N),每个区域一个向量。
- 处理完所有的region后,会得到一个NxN的矩阵,通过Sinkhorn操作转化为一个soft排列矩阵(进行行归一化和列归一化)

2.3模型
-
解决了输入问题,下面是模型主体部分。模型加入了一个控制信号,因此在生成时,不仅要考虑句子的合理性p(yt|R,I)在t时刻词语的概率,也要考虑生成的句子是符合给定region序列的
-
区域切换模块:region的选择是通过转换门gt(布尔类型)实现的:
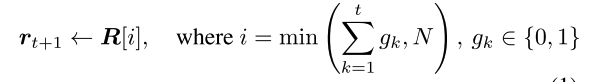
- LSTM输入:隐藏状态ht-1、当前图像区域rt和当前词语wt
- gt计算方法:首先计算一个哨兵值st,利用输出值和记忆细胞计算哨兵值。

- 然后计算哨兵和隐藏状态ht的相似度,以及隐藏状态和当前region每个之间的相似度

- 然后计算转换region的概率,

-
具有视觉哨兵的适应性注意力
- 区分视觉词和文本词
- 跟切换区域类似,计算哨兵值
- 然后利用Additive Attention计算region和哨兵值的相似度

- 然后可以得到一个加权向量,作为LSTM此时刻的输入
4.2019ICCV:Attention on Attention for Image Captioning
1.摘要
- 提出Attention on Attention
- 首先利用注意力结果和当前上下文生成一个信息向量和注意力门,然后将他俩相乘得到另一个注意力被叫做参与信息。应用AoA在编码器和解码器。
- CIDEr、BLEU-4:126.9、39.4
2.方法
2.1 AoA
-
信息变量 I,注意力门 G,都取决于注意力结果和当前上下文q

- v是注意力结果,然后g和i相乘,得到文中提出的新注意力
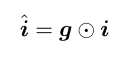
- 整体流程:


2.2AoANet for image captioning
- 编码器解码器都用AoA
2.2.1编码器
-
利用CNN或RCNN提取特征A=「a1,a2,…,ak」,先构建一个包含AoA的网络,再送往解码器。

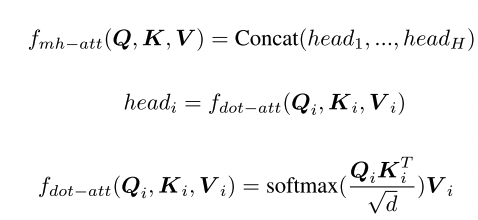

2.2.2解码器

- LSTM输入:有三个变量 a,ct−1,WeΠt,其中 a=1k∑i=1kai ,A={a1,a2⋯ak} 表示通过Faster-RCNN中RoIPooling层之后的图像区域特征, ct−1表示AoA模块的输出,WeΠt表示单词的词向量。

5.2020CVPR:X-Linear Attention Networks for Image Captioning
1.摘要
- CIDEr:132.8
- X线性注意力块同时利用空间和信道双线性注意分布来捕获输入单模态或多模态之间的二阶相互作用特征

2.方法
双线性池化
- SE全称Squeeze-and-Excitation,它注重通道信息。

- CBAM

-
包含CAM和SAM两个模块
- **CAM:通道数不变,压缩空间维度。**并行经过maxpool和avgpool,然后MLP 1/c和c倍,然后relu函数,在相加后sigmod得到channel attention。CAM与SEnet的不同之处是加了一个并行的最大池化层,提取到的高层特征更全面。


- **SAM:空间维度不变,压缩通道数。**关注的是目标的位置信息。通过最大池化和平均池化得到两个1xHxW的特征图,然后拼接,通过7x7卷积变为通道为1的特征图,接一个sigmoid得到空间特征。


-
先实现Q和K的双线性池化,例如特征为7*7*512,49x512,加权内积,最终融合后特征矩阵512*512,融合空间和通道信息求平均,Softmax归一化。
-
ELU函数,负数还有一点值,RELU负数为0。

3.X-LAN网络

- 编码器1+3个特征提取,解码器1个解码,输入:当前输入字wt、全局图像特征v、隐藏状态ht-1、上下文量ct-1,联合特征和词语编码输入
6.ECCV2020| Length-Controllable Image Captioning
1.摘要
- 生成长度可控的图像描述(更好比)

- 基于迭代的长度可控非回归图像描述模型,非自回归模型继承BERT,对输入潜入层进行修改,加入了图像特征和文本长度信息叫做length-aware BERT LaBERT。设计了非自回归解码器
- 设计了一种非回归解码器,长度可控
- [1,9]、[10,14]、[15,19]和[20,25]
2.方法
2.1将长度信息结合到自回归模型中
-
标题S从i=1到L,el长度信息,词信息ew,位置向量ep
-

-
长度感知自回归解码器
-
直接将上述单词表示公式替换到AoA中,模型的效果就提升了。
2.2非自回归模型
- 修改了BERT的潜入层,将图像信息和长度信息结合在一起,利用目标检测从图像I中检测出M个对象,
 ,还有区域特征
,还有区域特征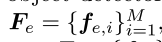 ,分类概率Fc,位置特征Fl
,分类概率Fc,位置特征Fl

- 训练
- 给定图像标题S*,首先确定他的长度级别,然后用【EOS】填充到长度的最大范围,然后用【MASK】随机替换描述中的m个单词构造输入序列S,最后模型根据输入的图片信息和序列S的信息来预测被替换掉的真实单词。

- 步骤:t=1时刻,将标题s初始化为连续的最大范围MASK,然后输入图像和文本,预测S中每个位置上的词汇表的概率分布pi。t=2,之后在选择置信度最低的n=T-t/T*Lhigh(T总迭代次数,t当前迭代次数,t越大,n越小)个词语替换为mask,再次进行解码,得到一个更好的句子,更新之心度
- 非自回归的方法计算复杂度与T相关而和生成描述的长度无关,降低了生成长描述的计算复杂度,并且还能在之后的步骤中修改早期步骤中犯的错误,这在自回归的方法中是不可行的。




温馨提示: 遵纪守法, 友善评论!