1.CVPR2020:In Defense of Grid Features for Visual Question Answering
1.摘要
- 目前对于边框区域特征无法进行合理的解释。文本重新检验了网格特征在VQA任务中的有效性,发现网格特征可以在获得相同准确率的情况下同时将推理速度提高一个新的数量级。网格特征会使得模型设计和训练更加简单,有助于端到端的训练和预测。时间节省大约48倍。
2.Introduciton
- 将边界框特征换为网格特征后,极大的加快了推理速度,由0.89s降低至0.02s,并且精度也略有提高。
3.From region to grid
3.1Bottom-Up Attention with Regions
- 自下而上的边界框特征的提取采用的是Faster R- CNN目标检测模型。在VQA任务中获得图像特征,一般进行如下两个步骤:
- 区域选择:先通过RPN确定候选框作为ROI;然后获取Top-K边界框
- 区域特征计算:根据第一步的区域结果,采用Rol Pool将框映射到特征区域上;最后包含了边界框特征和对应框内图像特征的组合特征就作为最终的图像特征。
3.2Grid Features from the Same Layer
- 将边界框特征转换为网格特征最简单的方式是看是否能在网络的同一层计算相关特征。
- 我们直接在原始的ResNet上提取C5层的输出作为网格特征,如图左。仅仅使用这个特征,实验中效果也不错。我们继续优化
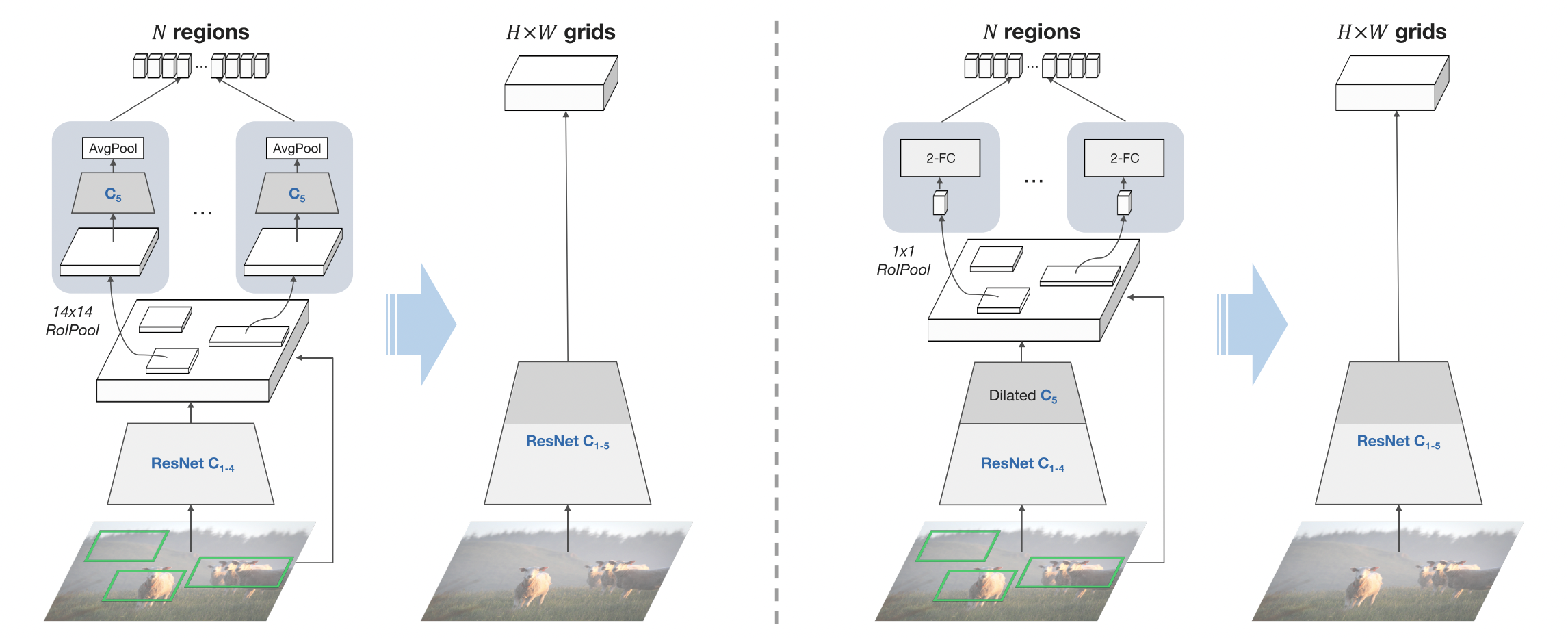
3.3 1x1 ROI Pool
- 调整的思路很简单,使用1x1 RolPool。也就是对于每个区域,只采用一个向量来表示他的区域特征,而不是Faster R-CNN中的三维tensor。使用1x1的操作意味着在网格特征上的每一个向量都会被强制包括这个区域的所有信息,间接上使得网格特征的信息更加丰富。
- 为了解决在其他维度特征缺失的问题,我们采用完整的ResNet作为主干网络。对于区域特征,我们在C5后增加了两个1024D的FC层,接受压缩后的向量作为输入。为图右。
4.Why do Our Grid Features Work?
- 为什么网格特征在VQA中表现较好:
- 输入图片的尺寸:图片尺寸越大,基于网格特征的VQA效果越好
- 预训练任务:预训练模型越强,VQA表现越好。
2.CVPR2021:RSTNet: Captioning with Adaptive Attention on Visual and Non-Visual Words
1.摘要
-
因为展平(flatten operation)操作引起的网格特征空间信息损失,以及transformer在区分视觉词和非视觉词有缺陷。
-
提出Grid-Augmented(GA)模块,将网格之间的相对几何特征结合以用来增强视觉表达。
-
然后,提出建立基于BERT的语言模型去提取上下文语言信息和在transormer解码器上提出Adaptive-Attention(AA)模块以用于自适应的测量视觉和语言的贡献程度,然后对词语进行预测。
-
结果
| BLEU1 | BLEU4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|
| 82.1/81.8 | 40.3/40.1 | 29.6/29.8 | 59.5/59.5 | 131.9/135.6 |
2.介绍
- 将GA模块和AA模块用于基于transformer的图像描述模型Relationship-Sensitive Transformer(RSTNet),对于每个编码器的注意力模块,结合网格特征的相对几何信息,计算出更准确的注意力分布。对于解码器,在视觉和语言线索的比例进行权衡,而不是直接预测单词。
3.Method
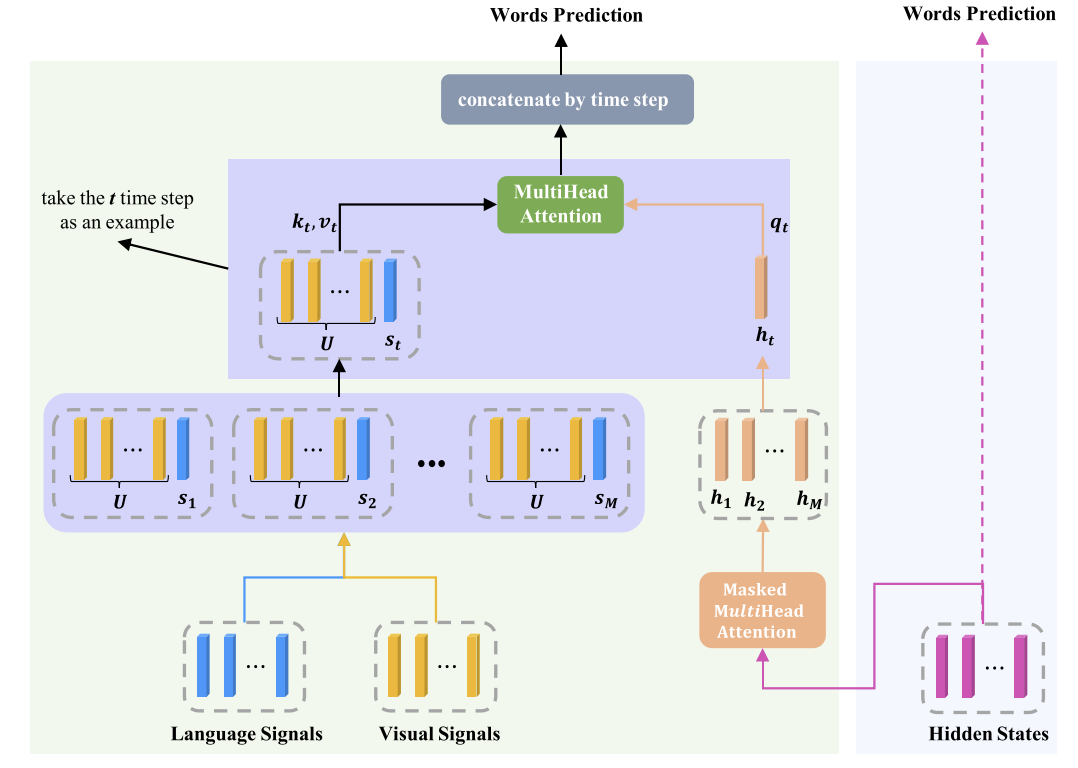
- 下图为RSTNet总体结构,先提取网格特征作为视觉输入,文本输入基于BERT提取,利用提出的自适应注意力模块测量视觉和文本的贡献,然后预测单词。
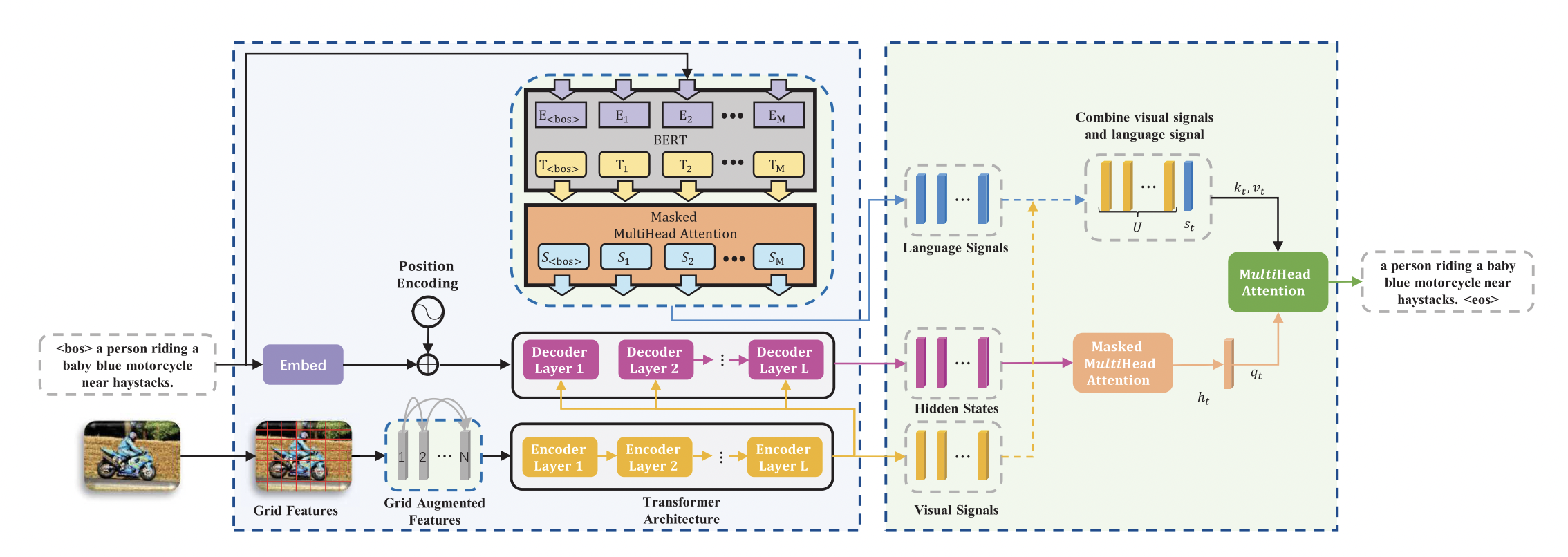
- 3.1网格特征表示;3.2语言特征表示;3.3介绍RSTNet;3.4定义了描述单词的可视化;3.5RSTNet训练细节
3.1Grid Feature Representation
- 利用论文《CVPR2020:In Defense of Grid Features for Visual Question Answering》提取(这篇论文证明网格特征不仅准确度不输给region feature,推理速度又快出一个量级)
- 在给定一组网格特征下,以往的方法通常是将其展开直接送入trnasformer编码器,这种操作会导致输入图像的空间信息丢失,如网格对的位置和关系。
- 本文提出Grid-Augmented(GA)模块去结合网格位置之间的相对几何关系。
- 计算每一个网格的2D相对位置,代表网格左上角的相对坐标。代表右下角相对坐标。然后计算网格的相对中心坐标,相对宽度,相对高度。
- 然后按照《CPRV2020:Normalized and geometry-aware self-attention network for image captioning.》《NIPS2020:Image captioning: Transforming objects into words.》方法计算区域几何特征,得到两个网络的相对几何特征。公式如下:
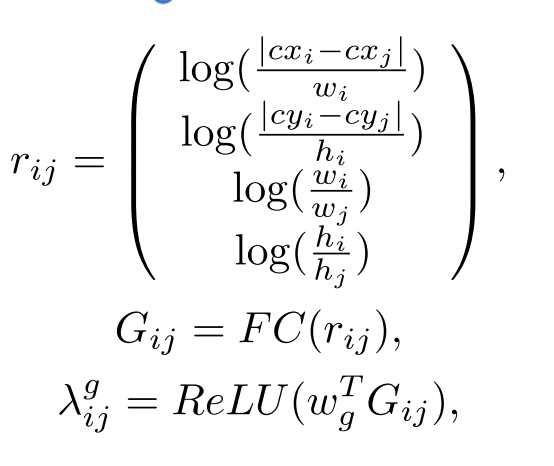
3.2Language Feature Representation
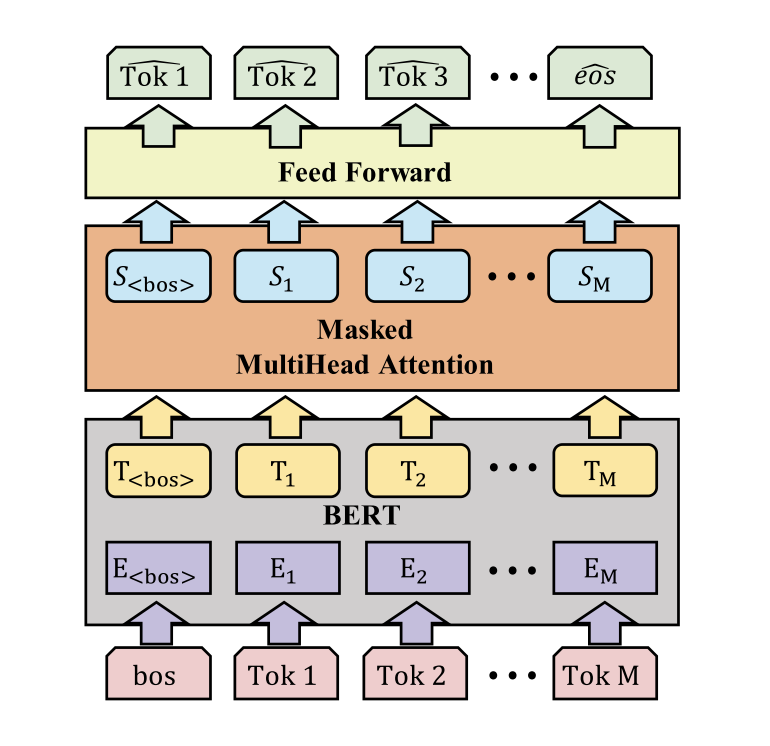
- 使用BERT提取语言特征,在bert上增加了一个类似于transformer层的mask注意力模块,使当前的词预测不受后一步的干扰。给定一个序列,这个模块将以一个时间步长的偏移逐个单词的预测这个序列,

3.3Relation-Sensitive Transformer(RSTNet)
- Encoder编码器:首先对原始图像进行展平,然后通过全连接层,ReLU,dropout。将维度。然后特征被送入transformer的第一个编码层中。
- Grid Augmented Module:结合3.1的网格几何特征,计算注意力。U是视觉特征。
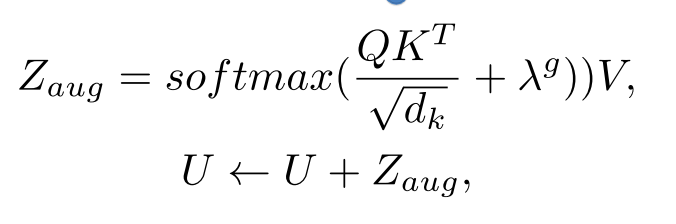
- Decoder:句子序列特征在用作transformer解码器输入之前,首先通过词嵌入和词序列位置结合编码,是编码器最后一层输出,是解码器输出的用于预测当前词语的隐藏状态。。
- Adaptive Attention (AA) Module:建立了自适应注意力模块。不直接使用隐藏状态来预测单词,而是使用3.2中的语言特征、编码器输出视觉特征和隐藏状态结合在一起。
3.CVPR2022:Injecting Semantic Concepts into End-to-End Image Captioning
加入语义概念的端到端图像描述
1.摘要
- 提出一种无检测器的图像描述模型,基于纯视觉transformer模型ViTCAP,使用网格特征而不提取区域特征。
- 为了提高性能,我们提出了Concept Token Network(CTN)来预测语义概念,然后将它合并到端到端描述中。CTN建立在视觉transformer上,通过分类任务来预测语义概念。
2.介绍
- (a)以往的RPN、ROI操作会带来计算负担以及效率低。(b)利用通用的视觉编码器作为检测器的替代品,产生网格特征以用于之后的跨模态融合。(72端到端117.3、79检测器129.3论文可看)。(c)提出ViTCAP,具有一个轻量级CTN网络,可以产生概念token。基于Vit改造,首先对图像进行编码,生成网格特征,然后在网格特征上应用CTN分支预测图像的语义概念。然后,多模态接受网格特征和Top-K个语义token进行解码。
- 创新点
- 提出无图像检测器模型ViTCAP,完全的transformer结构,利用网格特征而不是box特征区域。
- 将语义概念加入到端到端描述中。
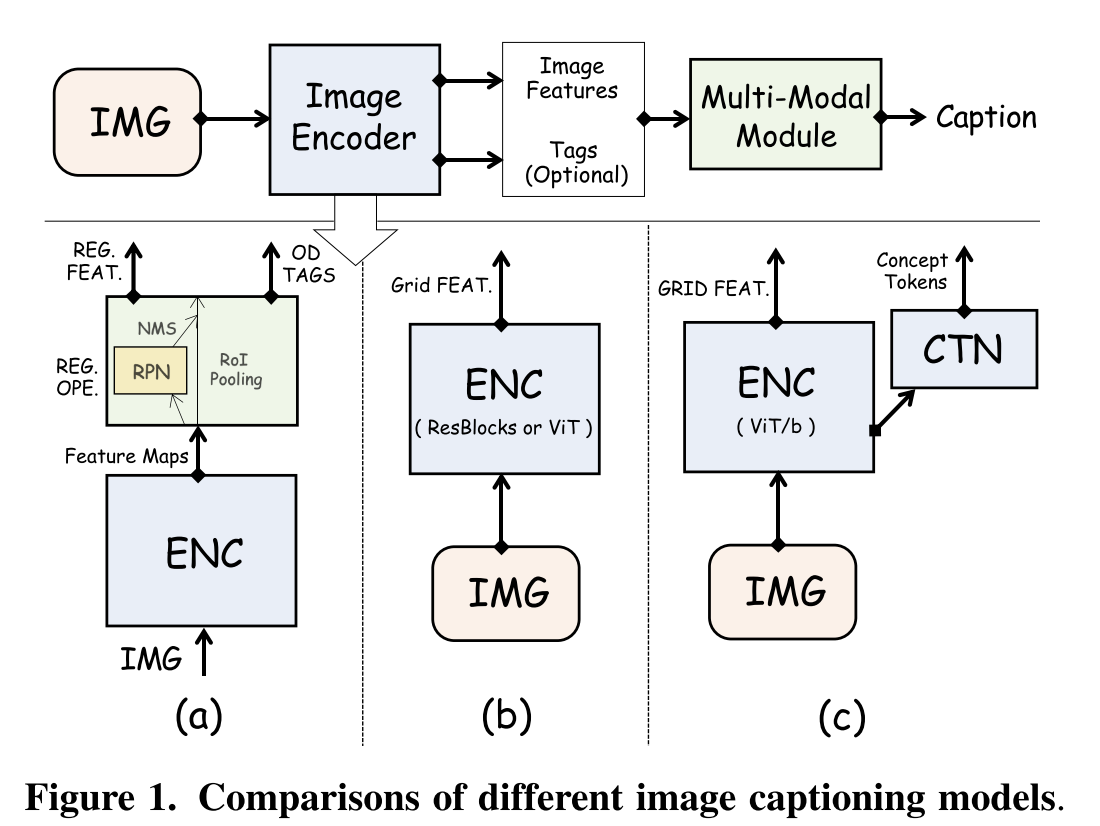
3.ViTCAP模型
- 现有的IC模型通常是由目标检测器模块(提取区域特征从图像)(文本)和多模态模块(multi-model MM)用于生成描述c。
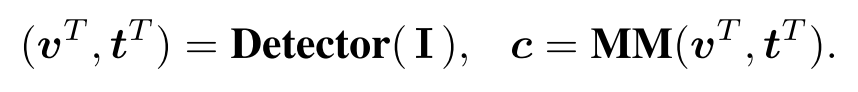
- 本文原始图像首先被送入图像编码器以生成中间表示()和最终网格表示。 然后,CTN分支将)作为输入并预测概念token(),然后跨模态交互并生成标题的多模态模块。 在所有模块中都采用了完全Transformer框架,但图像编码器和CTN模块不是特定于体系结构的。
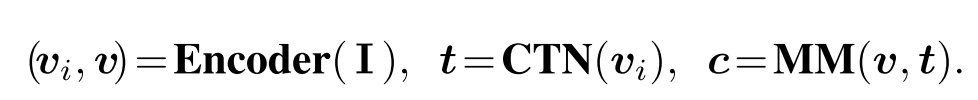
- 总体图如下:
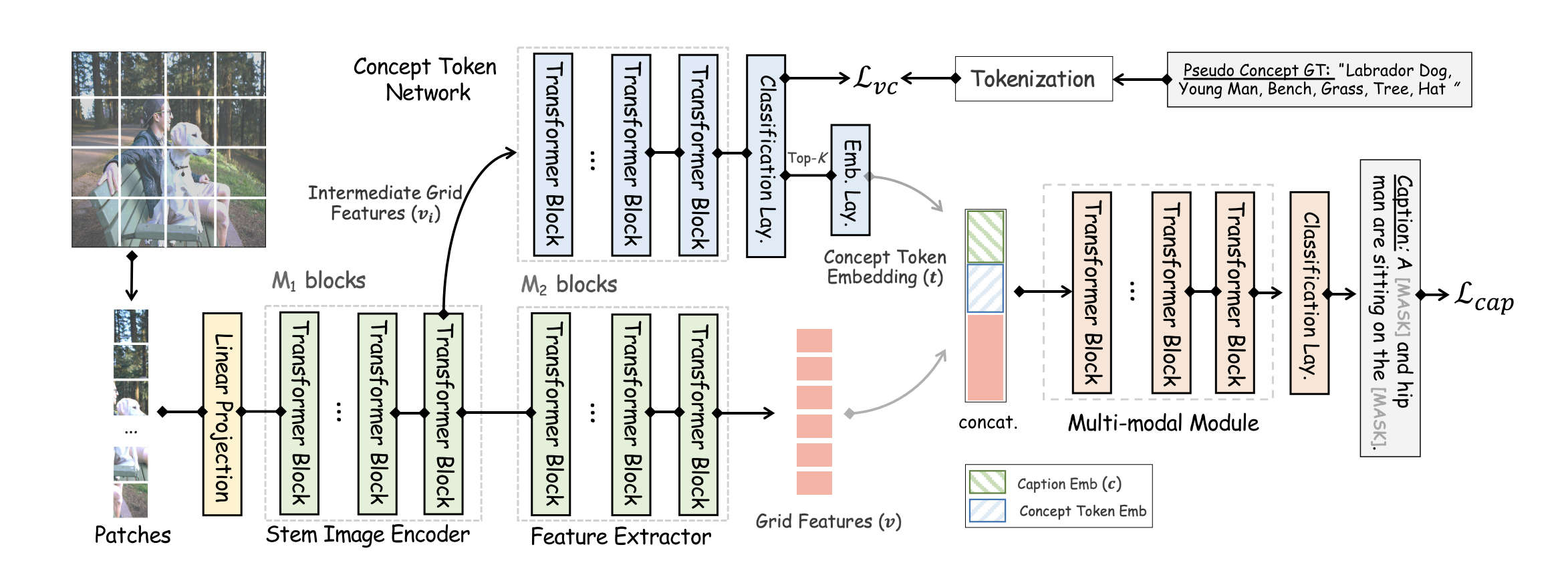
3.1Vision Transformer
- 使用ViT对图像编码,产生网格特征和。
- 把图片分成n个不相交的块,每个块的大小为,个数N为。然后把这些块展平送入加入【CLS】token,送入M个trnasformer块中。
3.2CTN concept token 网络
- 利用一个额外的模型,训练前50个词的概率,然后进行融合。
- 使用代码改进。前50个概率最大的词进行编码,和bert生成的单词,还有图像特征
3.3训练
- 第一步:训练CTN预测语义概念,输入图像,返回前50个概率最高的词
- 第二步:将CTN和特征进行concat进行融合,预测。
4.CVPR2022:DIFNet: Boosting Visual Information Flow for Image Captioning
1.摘要
- 提出一种Dual Information Flow Network(DIFNet)双信息流网络。将分割特征作为另一种信息源,以提高视觉信息对预测的贡献。为了最大限度的利用两个信息流,提出了一个有效的特征融合模块,成为Iterative Independent Layer Normalization(IILN)迭代独立归一化层,他可以浓缩最相关的输入,同时在每个信息流中重新训练特征于模态的信息。
- 结果CIDEr:136.2.SOTA
- 利用的代码
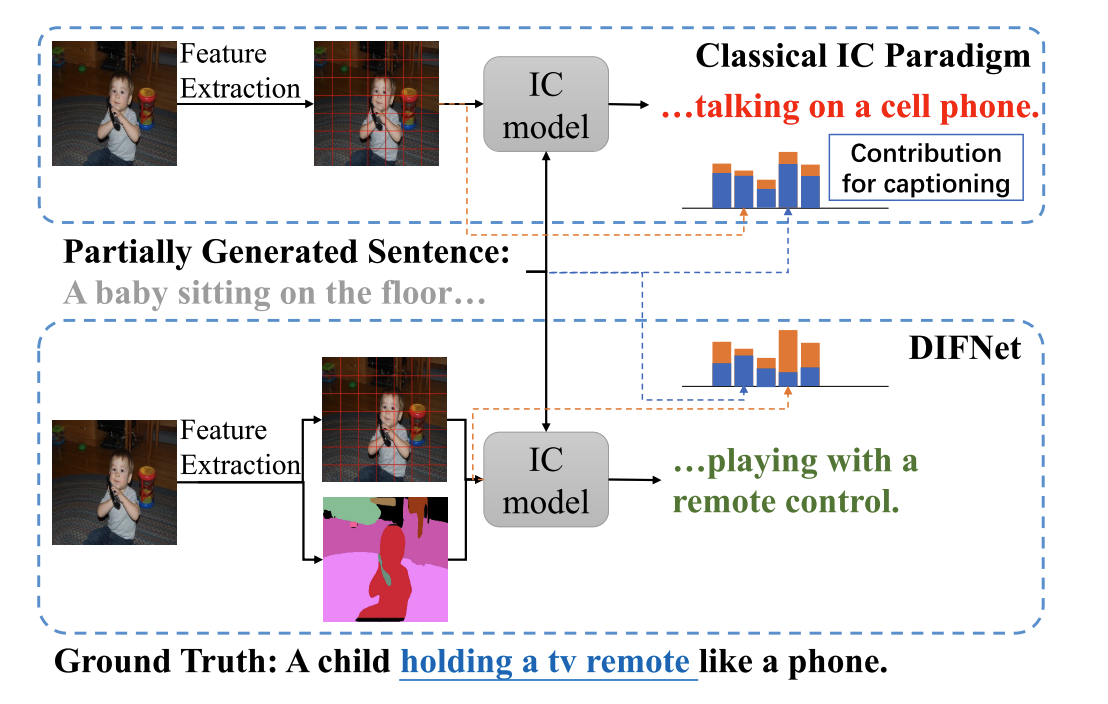
2.Introduction
- 文章使用分割图,区域语义和网格特征自然对其,如上图下。分割图可以看作是空间语义指导,为网格特征提供了一个细粒度的上下文,便于进行图像理解。
- 另一方面,像素级类别信息有助于纠正网格特征中不可靠信息而误判的类别。
- 空间信息也有助于推断潜在的语义和空间关系。
- 提出双信息流网络DIFNET,将分割特征作为另一视觉信息源来补充网格特征,从而提高视觉信息对可靠预测的贡献。
- 提出IILN层,将两个信息融合。
- 采用跳跃链接增强编码器和解码器内部之间的信息流动。
3.准备工作
- 给定图像,可以由一个句子来描述,由个词组成。,表示为从图像中提取的网格视觉特征个。我们将网格特征编码成连续的表示序列,以输出句子。
- ,是语言解码器,是视觉编码器。
4.Method
- 讲解我们提出的DIFNet,使用分割特征和跳跃连接来增加视觉信息流。4.1描述分割特征;4.2研究VSA融合方法,描述我们的IILN融合方法来融合分割特征和网格特征;4.3使用跳跃连接;4.4训练
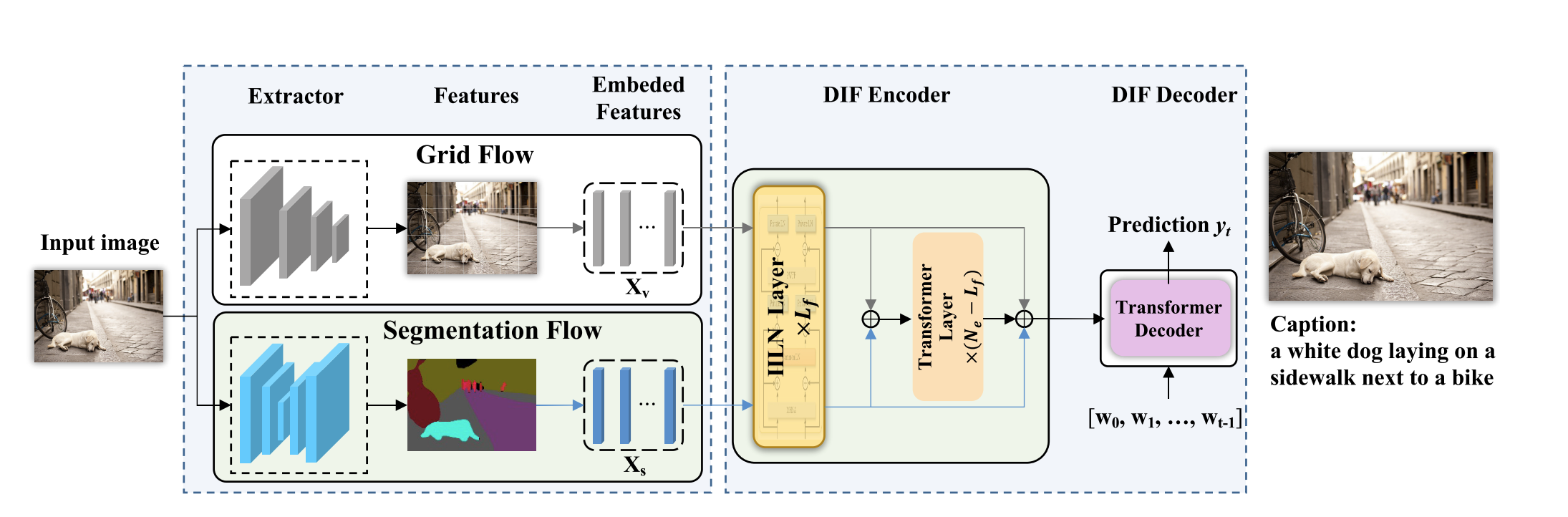
4.1 Segmentation Feature
- 提取出语义分割图,将其转化为语义特征向量,C是类别数量。
4.2Fusing Grids with Segmentations
- 首先研究了一种融合策略VSA,然后提出我们的融合方法IILN
- Fusion via Vanilla Self-Attention
- 简单的使用transformer来编码和融合两个输入序列。给定网格输入 和分割输入,将两个输入后,拼接。
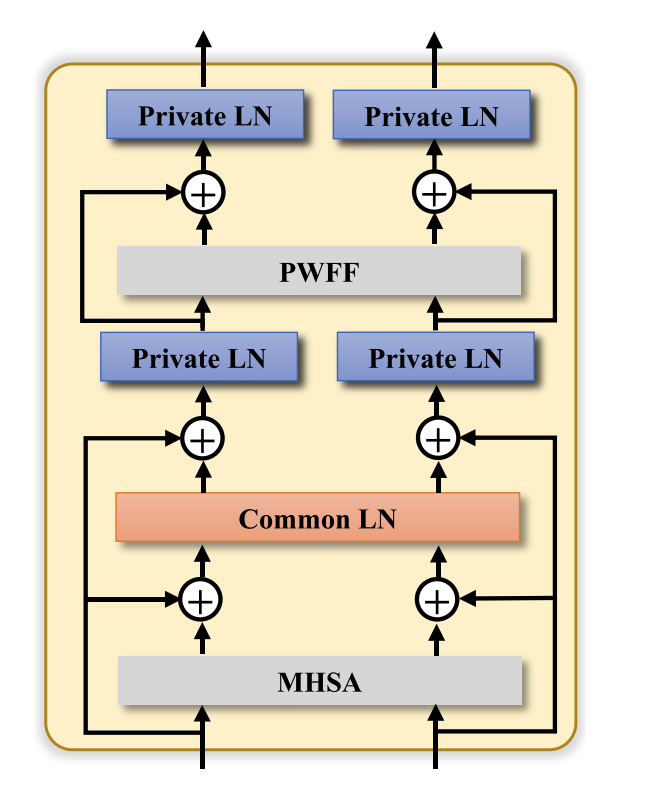
- Fusion via Iterative Independent LN.
- MHSA多头自注意力,PWFF位置前馈网络。在MHSA上添加跳跃连接,为了防止一些不被注意的特征有所损失。
-
5.CVPR2022:Comprehending and Ordering Semantics for Image Captioning
1.Abstract
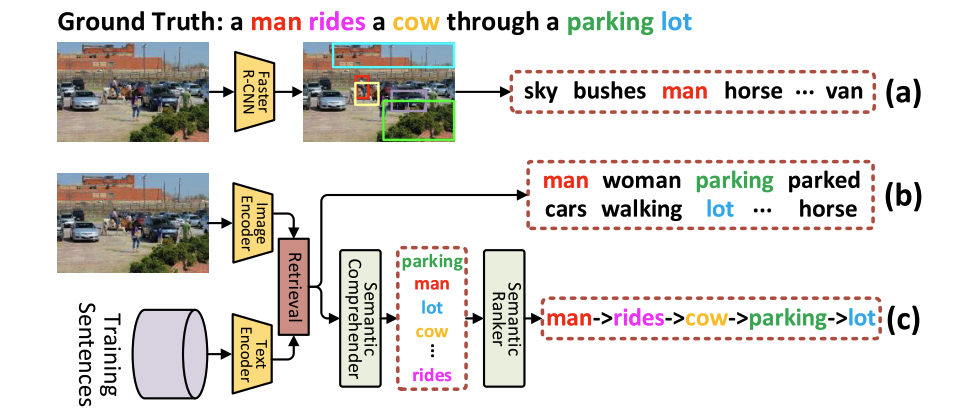
- 提出了一种新的transformer结构,Comprehending and Ordering Semantics Networks (COS-Net),将语义理解和语义排序统一到一个体系中。在技术上,检测图像中存在的每个单词作为语义线索,然后设计出一个信息语义理解器,过滤掉原始线索中不相关的语义词,同时推断出缺少的相关语义词(比如fasterrcnn中只识别目标主体人、马、狗,对花草树天空等没有挖掘出)。然后排好顺序输出句子。
2.Introduction
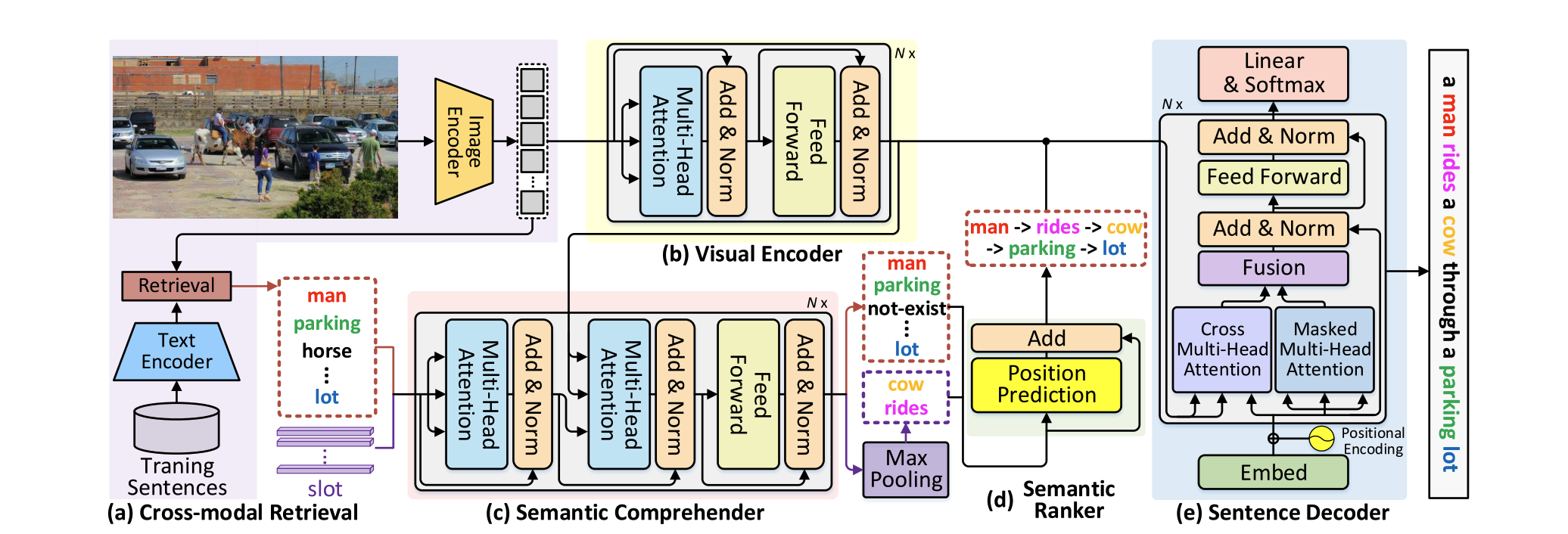
3.Method:COS-Net
3.1Visual Content Encoding
- 利用多个堆叠的transformer块去编码图像为token。输入图像,利用CLIP(主干RESNet101)提取网格特征,并结合全局特征。将全局特征和网格特征进行连接得到。然后进行自注意力编码得到,第i块transformer为:
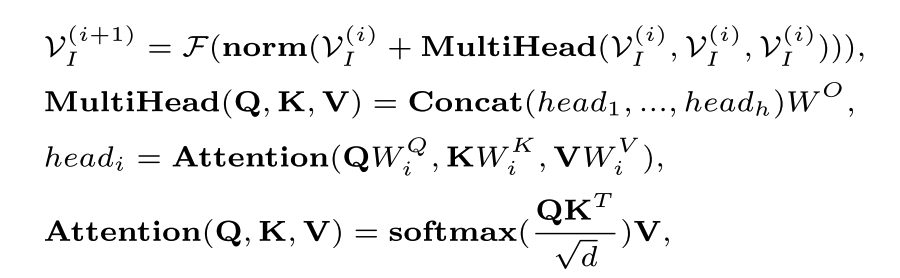
3.2Semantic Comprehending语义理解
3.2.1跨模态检索
- 利用CLIP为每个图像搜索语义相关的句子。找出语义相关的单词进行排序。利用和代表从CLIP提取到的视觉特征和文本特征。以输入图像作为搜索Q,根据和每个描述之间的余弦相似度,检索出前K个caption。然后取出介词代词等词语,生成语义单词集合,作为主要语义线索。
3.2.2语义理解
- 将网格特征作为精细语义线索的条件,为了能够重建丢失的相关语义词,我们使用附加的参数语义查询,也就是将语义线索和图像特征送入transformer。得到单词概率的排序。
3.3语义排序
- 结合位置信息进行预测,输出排好序的单词
3.4解码
- 将预测每个单词作为输入,结合mask attention进行融合进行预测非实体词。




温馨提示: 遵纪守法, 友善评论!