笔迹鉴定(二)
1.论文9
State of the art in off-line writer identification of handwritten text and survey of writer identification of Arabic text
离线书写人识别技术现状及阿拉伯文本书写人识别综述
1.1最小距离分类器
-
最小距离分类器通过测量从测试样本到训练模式的距离并选择最近邻所属的K-nearest classes(KNN)来对新模式进行分类。
-
K最近邻(kNN,k-NearestNeighbor)分类算法。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
-
当预测一个新的值 $ x$ 时,根据它距离最近的 $ K$ 个点是什么类别来判断 $ x$ 属于哪个类别
-
绿色的点是我们要预测的点,假设 $ K=3$ 。那么KNN算法就会找到距离他最近的三个点,看看哪种类别多一些。图中蓝色三角形为两个,红色圆形为一个。所以新的绿色点就被归类到蓝色三角形了。
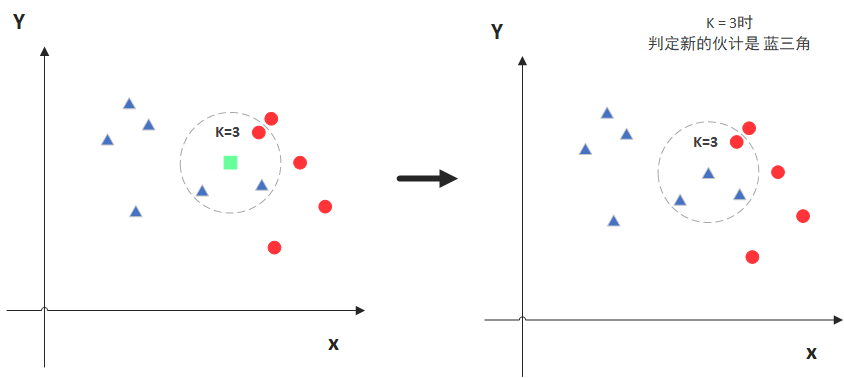
- 但是,当 $ K=5$ 的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。所以$ K $的取值是很重要的。
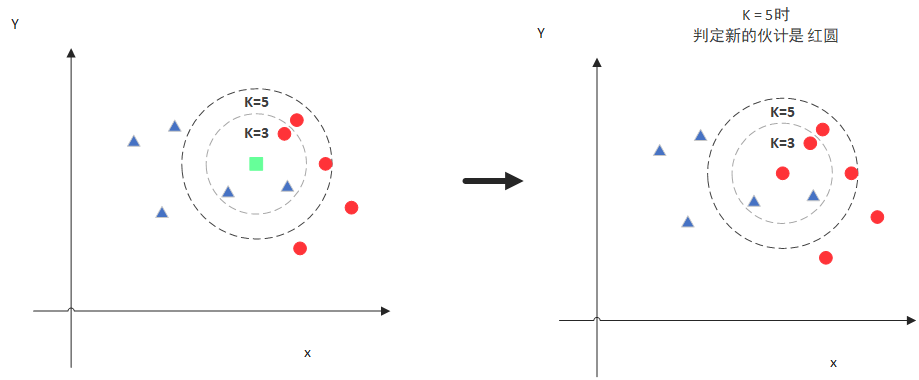
- K值的选取和点距离的计算是KNN中最重要的。
- 常见的有曼哈顿距离计算,欧式距离计算等等
- 二维空间两个点的欧式距离计算公式为:
- 拓展到多维空间的欧式距离为:
- K值的选择:通过交叉验证,选取一个小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K。
2.论文10
Offline Text-Independent Writer Recognition: A Survey
离线文本书写人识别
- 当作者数量增加时,基于频域特征的方法的性能严重下降,并且空间分布特征在捕获个体特征方面优于频域特征和形状特征。
- 频域特征:图像经过傅立叶变换后得到频谱图,就是图像梯度的分布图。设置手写体在频域中的全局特征。
- 空间分布特征设计手写体的局部空间结构特征。
3.论文12 Personal identication based on handwriting
Personal identication based on handwriting
书写人身份识别
- 图像归一化:归一化后所有像素值都在[0,1]之间。
- 特征提取:多通道Gabor滤波(MGF),灰度共生矩阵(GSCM???GLCM)
- 灰度共生矩阵:指的是一种通过研究灰度的空间相关特性来描述纹理的常用方法。由于纹理是由灰度分布在空间位置上反复出现而形成的,因而在图像空间中相隔某距离的两像素之间会存在一定的灰度关系,即图像中灰度的空间相关特性。
- 用了两种分类器:加权欧式距离(WED)和K-近邻分类器(KNN)
4.论文77 A Comparison of Clustering Methods for Writer Identification and Verification
书写人识别和鉴定的聚类方法比较
- 通过聚类获得给定笔迹样本的字形码本。(k-means(最简单的聚类,以k为距离划分), Kohonen SOM 1D and 2D.)
- 分割方法:靠近上轮廓的下轮廓的最小值处分段,然后经过某种处理,储存下来。

5.论文96Offline Writer Identification Using Convolutional Neural Network Activation Features
离线书写人识别,利用卷积神经网络
5.1输入层
- 一维卷积神经网络的输入层接收一维或二维数组,其中一维数组通常为时间或频谱采样;二维数组可能包含多个通道;二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组。由于卷积神经网络在CV领域应用较广,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和RGB通道。
- 使用梯度下降算法学习(是迭代法的一种,用于求解最小二乘问题,在求解损失函数的最小值时,可以通过梯度下降法一步一步迭代求解,得到最小化的损失函数和模型参数值)
- 若输入数据为像素,可以将[0,25]的原始像素归一化为[0,1]区间,输入特征的标准化有利于提升卷积神经网络的学习效率和表现。
- 卷积神经网络的隐含层包含卷积层、池化层和全连接层3类常见构筑,
- 卷积层的功能是对输入数据进行特征提取,其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏差量(bias vector),类似于一个前馈神经网络的神经元(neuron)
6.常用的图像预处理手段
- 去噪:使用滤波器去除
- 二值化:小于阈值设置为0,大于设置为255
- 边缘检测:本质上是一种滤波算法。数组点乘边缘算子,然后再取绝对值,对x、y轴共进行两次滤波,得到的结果进行平方求和开根号得到当前像素点的图像梯度,就求出了边缘。
- 倾斜校正
- 文本提取
7.分类器的选择
- 小类别集且数据量够多时,可以训练数据得到优秀的模型
- 当类别多,但每个类别少时,基于距离度量的简单分类器性能更稳定
8.特征的分类
8.1纹理特征
8.1.1频域特征
-
在图像处理中,时域可以理解为空间域,处理对象为图像平面本身。频域就是频率域,是描述信号在频率方面特性时用到的一种坐标系。自变量是频率,即横轴是频率,纵轴是该频率信号的幅度,也就是通常说的频谱图。频谱图描述了信号的频率结构及频率与该频率信号幅度的关系;
-
将笔迹的图像转化为频域信号,通过提取频域信号中的若干属性作为笔迹的特征。
8.1.2空间分布特征
-
空间分布特征是直接统计边缘像素、关键点以及文本行中特定的空间结构来表示笔迹的个性化差异。
-
灰度协方差矩阵,也是统计纹理特征的一种方法
-
灰度游程直方图/灰度游程矩阵:一幅图像的灰度游程矩阵反映了图像灰度关于方向,相邻间隔和变化幅度等综合信息。灰度游程矩阵是对分析影像的局部模式和其排列规则基础之一。灰度游程矩阵可以实现对一幅图像中同一方向同一灰度值连续出现个数的统计。在一幅图像上,在某一方向上连续的像素点具有相同的灰度值,灰度游程矩阵就是通过对这些像素点的分布进行统计得到纹理特征。
-
梯度:相邻两个像素之间的差值。可以利用求出来的梯度,增强图片对比度,清晰轮廓。(梯度加原有点像素)
-
边缘方向特征:一条边缘和中心夹角的概率分布直方图来表示特征
-
边缘铰链特征:两条与中心相连通的边缘像素的夹角
-
尺寸不变特征变换(Scale invariant feature Transform,SIFT):目标是解决低层次特征提取及其图像匹配应用中的许多实际问题。SIFT算法主要包括两个阶段,一个是SIFT特征的生成,即从多幅图像中提取对尺度缩放、旋转、亮度变化无关的特征向量;第二阶段是SIFT特征向量的匹配。SIFT方法中的低层次特征提取是选取那些显特征,这些特征具有图像尺度(特征大小)和旋转不变性,而且对光照变化也具有一定程度的不变性。此外,SIFT方法还可以减少由遮挡、杂乱和噪声所引起的低提取概率。
-
加速鲁棒特征Surf(Speeded Up Robust Features):Sift尺寸不变特征变换算法的优点是特征稳定,对旋转、尺度变换、亮度保持不变性,对视角变换、噪声也有一定程度的稳定性。缺点是实时性不高,并且对于边缘光滑目标的特征点提取能力较弱。
Surf改进了特征的提取和描述方式,用一种更为高效的方式完成特征的提取和描述。
8.2形状基元
- 前提假设:书写人被视为一个随机但服从某种规律的基元产生器。而笔迹书写过程可以看作多个基础基元零件被组成一个个文字的过程。当笔迹的字足够多时,每个基元零件出现的概率就可以用来表示书写人的特征。
- 论文77:利用聚类讨论可能对基元码本可能产生的影响
8.3深度学习特征
9.公共数据库
9.1中科院CASIA数据集
CASIA-OLHWDB1.0 :手写单字,171 个英文数字符号,3866 个常用汉字(其中3740个属于GB2312 - -级汉字),420套,分别为420个人书写。总共1,694,741个有效样本,分别存在420个POT文件中。
CASIA-OLHWDB1.1 :手写单字,171个英文数字符号,3755个GB2312级汉字,300套,分别为300个人书写。总共1,174,364个有效样本。分别存在300个POT文件中。
下载地址其他的数据集需要申请。
9.2哈工大HIT-OR3C数据集
HIT-OR3C由5个子集组成 (GB1, GB2, Digit, Letter, 和Document),GB1和GB2是汉字标注库GB2312-80内2个子集的简写。GB1, GB2, Digit, 和 Letter子集已采集完成122套,共832,650 个手写汉字。Document子集包括10个从新浪网收集的文档,每个文档采集2套,共收集了20套。文档子集共有77,168个字符, 覆盖2,442个字符,其中2,286个来自GB1,97个来自GB2,49个来自Letter, 10个来自 Digit。
9.3华南理工SCUTCOUCH-2009数据集
SCUT-COUCH2009是一款包括12个子集的完整数据,它们分别是:中文词组、国标一级汉字、国标二级汉字、国标一级汉字对应的繁体字、汉语拼音、英文字母、阿拉伯数字、常用符号、Word8888、Word17366、Word44208和联机文本行数据。每套完整的SCUT-COUCH2009包括6,763个GB2312-80单汉字,5401个Big5繁体字,1384个和GB2312-80一级字库相对应的繁体字,8,888个常用的中文词组,17,366个常用中文词组,摘自《现代汉语大辞典》(第四版)的44,208个词组,2,010个汉语拼音,184个其他符号(包括字母、数字和常用符号)和8,809行联机文本行;现在版本的SCUT-COUCH2009使用PDA或手写屏进行采集,已完成了由190多人书写的完整的数据,字符总数超过3.6百万个。
下载地址(需要申请)
10.边缘共生对
问题:怎样选择的边缘像素对,(45和135),(135和202.5)就是随便选的吗?为啥没有270度
11.边缘共生特征与 SIFT 描述子直方图结合
-
SIFT:SIFT即尺度不变特征变换,是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
-
然后利用直方图统计领域内像素对应的梯度和幅值:梯度方向角为横轴刻度,取45度为一个单位,那么横轴就有8个刻度;纵轴是对应梯度的幅值累加值。
-
SIFT算法特点:
- 具有较好的稳定性和不变性,能够适应旋转、尺度缩放、亮度的变化,能在一定程度上不受视角变化、仿射变换、噪声的干扰
- 区分性好,能够在海量特征数据库中进行快速准确的区分信息进行匹配
- 多量性,就算只有单个物体,也能产生大量特征向量
- 高速性,能够快速的进行特征向量匹配
- 可扩展性,能够与其它形式的特征向量进行联合
-
在不同的尺度空间上查找关键点,并计算出关键点的方向
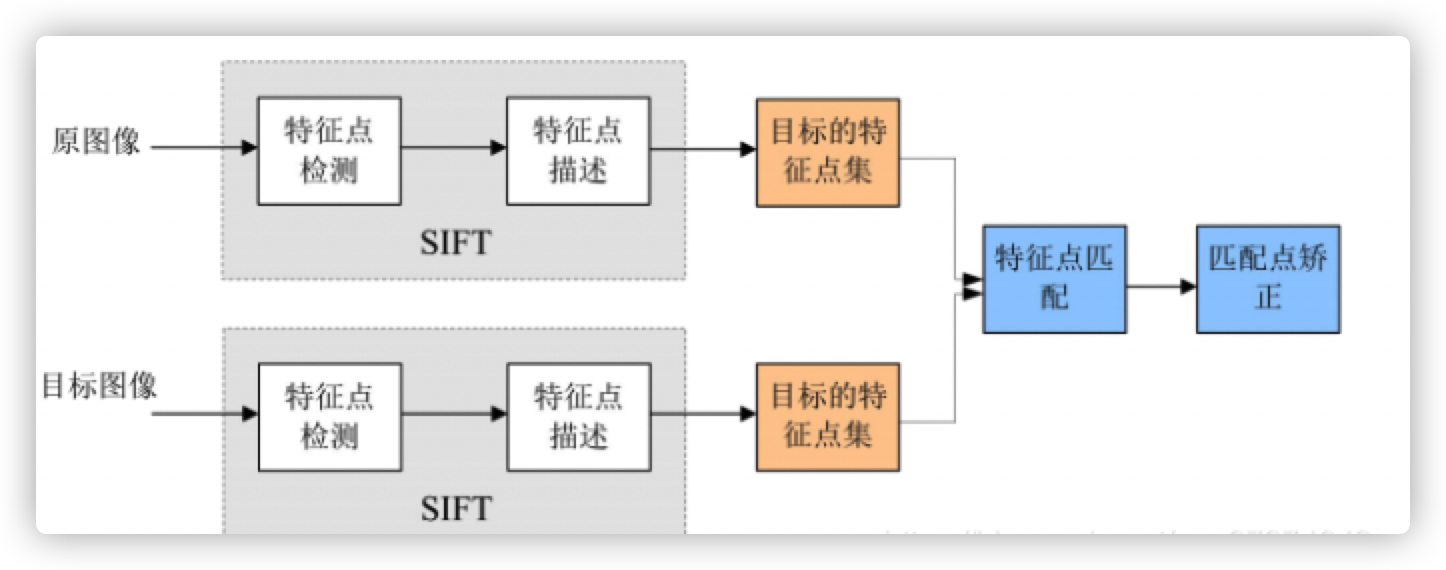
- SIFT关键流程:
- 提取关键点:关键点是一些十分突出的不会因光照、尺度、旋转等因素而消失的点,比如角点、边缘点、暗区域的亮点以及亮区域的暗点。此步骤是搜索所有尺度空间上的图像位置。通过高斯微分函数来识别潜在的具有尺度和旋转不变的兴趣点。
- 定位关键点并确定特征方向:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。然后基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
- 通过各关键点的特征向量,进行两两比较找出相互匹配的若干对特征点,建立景物间的对应关系。
- 最后用SIFT提取到的关键点与边缘元共生对融合特征,就完成了特征提取。




温馨提示: 遵纪守法, 友善评论!